
Hi,
I know that if I use soundfiler with the message "read -resize soundfile.wav array". I can get the size of the soundfile. However, this method is limited to short wavfile. I am trying to load 30 minutes long soundfile into pure data. I can read it with readsf (thank to the help of this forum).
However, readsf will not give me the size of the file. It will just bang at the end of the file.
I have found a clumsy way. but I am open to any better solution.
Thanks
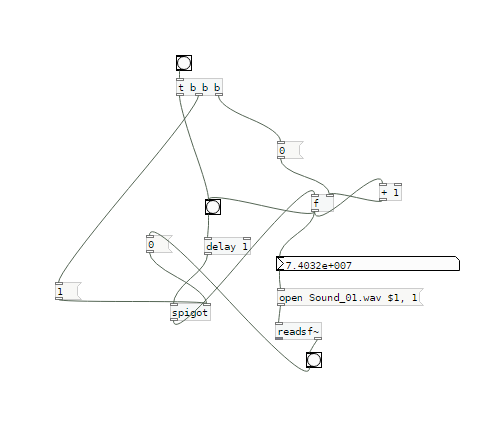
-
Get the size of a large wav file without loading it
-
With not short numbers, Pd runs into single precision truncation.
So this will not be very accurate.
(Also, Pd's message schedueling has a resolution of 64 samples)In your screenshot patch above, you can use [realtime] with [readsf~] to know about how long the play time has been.
But if you don't want to load:
Here is another thread with [soundfile_info], - where I tried to get the info running [soundfiler] on a different cpu-thread with [pd~], but it still glitches for me with very long files (why?):.
And this is my attempt with [file size]:around 1minute.pd [EDIT: updated] and 30 minutes
getdur.pd [Updated, again](Still wondering why Vanilla can't read the header info only, without loading the whole file?)
Edit: with [file handle] it might actually be possible to read the info out of the header. -
@lacuna said:
Here is another thread with [soundfile_info], - where I tried to get the info running [soundfiler] on a different cpu-thread with [pd~], but it still glitches for me with very long files (why?):
Here, I wonder if it would be feasible for soundfiler to be changed so that it could use a lower priority background thread for filesystem access. There isn't any need, really, for it to lock up the engine while doing time-unbounded things with the filesystem. Soundfiler pops out a message when it's done; I can't see any reason why this must be synchronous -- just load up in the background and the patch continues in response to the output message.
SuperCollider doesn't glitch the audio when manipulating soundfiles because 1/ the audio server pushes expensive ops like file access onto a lower priority thread, running a command queue and 2/ for this topic's initial question, you can query a soundfile's header without loading the contents and this is in a completely separate process from the audio engine.
I'm just wondering if anyone knows whether the blocking behavior of soundfiler is due to a necessary design factor or if it's just because nobody implemented a background thread for it.
(Still wondering why Vanilla can't read the header info only, without loading the whole file?)
Minimal core

hjh
-
@ddw_music agree
I'd say the scheduler is very basic. (My favorite topic ...It also bugs me, that there is even no difference in priority of the GUI to let's say Midi for example.)On the other hand, each time Pd breaks its deterministic order - things tent to get messy:
As in my 1minute patch above:
[writesf~] takes some time to 'open' a new file, and if [fast-forward 60000( follows next to [open( , the wav-file gets corrupted (at least on my machine), that's why I added a delay after some guessing around.
But agree, if it would output its status.(Still wondering why Vanilla can't read the header info only, without loading the whole file?)
The helpfile of soundfiler says:
"If no array name is given, no samples are read but the info is provided anyway."
Not sure if this is actually the case, as I get drop outs occasionally. Does it read the header only?
But sometimes there is no dropout even for > 1 hour files. Confusing. Might be a slow harddrive/os/filesystem?Later I have succesfully been using the shmem lib, to accomplish expensive tasks in an asynchronous manner: Sharing memory between multiple Pd instances. Easy to use, but might be overkill in this case.
That would be better than [pd~] here, as the [pd~] child still is running synchronously to the parent (that's also the reason why pd~'s child won't run in fast-forward: https://github.com/pure-data/pure-data/issues/1126)
[Edit: @porres not entierly sure... as there is no real answer to @Spacechild1 's objection and last posts not being clear: "this has been fixed? / yes" ] -
@lacuna @hjh You can grab the header like this since Pd 0.52.... soundfile_info_vanilla.pd
There is more in the header but I was only interested in the first 28 chunks of a .wav file.
I am still trying to work out how to interpret/convert the data though...... so I hand it over hoping someone "just knows".....
Some of it ...... eg RIFF..... 82 73 70 70 is easy..... but some of the others?
Hopefully no dropouts when banged.
David.

-
@lacuna said:
The helpfile of soundfiler says:
"If no array name is given, no samples are read but the info is provided anyway."
Not sure if this is actually the case, as I get drop outs occasionally. Does it read the header only?As Ross Bencina points out in a justifiably famous article, "All sources of audio glitches within your code boil down to doing something that takes longer than the buffer period. ... The main problems I’m concerned with here are with code that runs with unpredictable or un-bounded execution time. That is, you’re unable to predict in advance how long a function or algorithm will take to complete. ... Doing anything that makes your audio code wait for something else in the system would be blocking. This could be acquiring a mutex, ... snip snip..., waiting for data to be read from disk..." (hmmmm).
If [soundfiler] is blocking for filesystem access and it affects the audio thread, then it would explain the glitches. In that case, it might not even need to read a large amount of data -- if the data aren't in the filesystem RAM cache already, spinning the HD to the right speed and pushing the drive head to the right position could take longer than the available time. A SSD might fare better but there are no guarantees. Filesystem access should be treated as time-unbounded and not safe for real-time audio -- even just reading a header.
IOW if my guess is correct about [soundfiler]'s behavior, then it is breaking Bencina's prescriptions for real-time safety = bug. ("Especially if your software is going to be used to perform to a stadium full of fans... you do not want your audio to glitch. Period.")
SC's solution (shunt time-unbounded ops into a queue running in a lower priority thread) is one correct way. There might be others. I just wonder why Pd seems not to be doing that.
hjh
-
@ddw_music Which is why I only use [readsf~] for live performance, and preload all tables necessary with [soundfiler].
It takes a while to fine tune a performance machine, but once done it can be very stable if you refuse all updates.
That is a good article, that you linked to, and the Native instruments faq for "tuning tips" is very thorough ..... https://support.native-instruments.com/hc/en-us/search?utf8=✓&query=windows7+tuning+tips
David. -
@whale-av said:
It takes a while to fine tune a performance machine, but once done it can be very stable if you refuse all updates.
Sure. It occurred to me later that there are really just a couple of ways to look at Pd's glitches:
- It's a bug and the devs ought to fix it.
- Or, it's just the boundary of Pd usage, and you have to accept it.
The problem with no. 1 is that there are probably patches out there something like this:

... where the order of operations depends on [soundfiler] blocking until it's really finished. IMO that's a bad structure but people create all kinds of bad structures in normal usage
It's probably better like this:

... but there's no way to know how many user patches out there follow the first pattern. Making [soundfiler] asynchronous would break those patches, so this probably won't happen even though there would be good reasons to change it.
The problem with no. 2 is that it places severe limits on Pd's capability as an improvisational tool. That is, I can use Pd in the classroom, but as an improviser, not for audio processing on stage.
hjh
-
A non-portable/non-vanilla but quick and simple way is [command] or [shell] combined with what ever command line application can do what you need. sox/soxi comes with most linux distros and possibly OSX, no idea about windows.
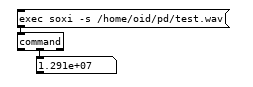
-
@JenniferM I had some time to understand the header format....... little endian on my machine so the reverse of what I first thought.
For a .wav file [soundfile_info_vanilla] should return the sample-rate accurately, and the total samples to within a very small margin of error (because the header size is uncertain)..........
Of course for a large file the error is hidden by the reduced representation in Pd.
test.zip
If it doesn't cause dropouts then it could be useful for others that just want to get the size or the sample-rate or some other info.
If the results are wrong on your computer then change [list append] to [list prepend] in [soundfile-Hex].
David. -
in this pr @Spacechild1 says it should be easier to implement the threaded
[soundfiler]if it gets merged (and to write asynchronous externals also)
https://github.com/pure-data/pure-data/pull/1357
it seems like in the current pr for threaded soundfiler https://github.com/pure-data/pure-data/pull/655 it says the open is still done on the main thread, but it seems like it should be on another thread as well since it can need disk access




