-
ddw_music
posted in technical issues • read more@jameslo said:
But wait! I just checked the harmonics of a full wave rectified {cos~] and all the even FFT terms have positive magnitude, so this post appears to be correct. And now I just reran my first test and set my "top only" slider to exactly 2 and am getting the fundamental + all even harmonics. Why am I getting so tripped up by this?!!!
Hm, yes, the argument about double frequency does make sense. I guess neither of us considered the possibility that the initial test may have been flawed.
What actually were your settings for the two sliders in the first screenshot? I'm curious to try to reproduce it but I can't see what the numbers are.
hjh
-
posted in technical issues • read more
If it's tabwrite~ then you'd have to bang it precisely when it should loop back around to the beginning of the array. That might be doable at 48 kHz because 48000 is divisible by 64. 44.1 kHz is likely to be trickier.
For this usage, I'm a fan of count~ and poke~ in the cyclone library.
hjh
-
posted in technical issues • read more
@jameslo said:
I think it's things like this that misled me in the first place
YouTube channel House of El-AI calculates, based on Google's number of daily queries scaled down to an hour and multiplied by a ~9% hallucination rate, that Google's AI overview serves up 57 million wrong answers every hour.
hjh
-
posted in technical issues • read more
As you noted, [poly] works in the direction of note number --> channel: you give it a note number; it gives you a voice number, or channel; and then when you tell [poly] that you want to release that note number, it will retrieve the channel number.
The catch for your case seems to be "when a new note comes in to a particular channel" -- which sounds like the voice/channel assignment is happening independently of anything [poly] might do.
Does this accurately describe the messaging?
- Note on, say, f# above middle C = channel 2, note 66, velocity > 0.
- New chord overwrites all the strings, including, say g above middle C.
- g is on the high E string, so f# needs a note off: channel 2, note 66, vel = 0.
- Then note 67 gets a note-on.
Is that right?
In that case, could you not simply use an array, indexed by channel number? You have a sequential index that's coming in from outside. Arrays operate based on sequential indices. That sounds simpler to me than using a bag.
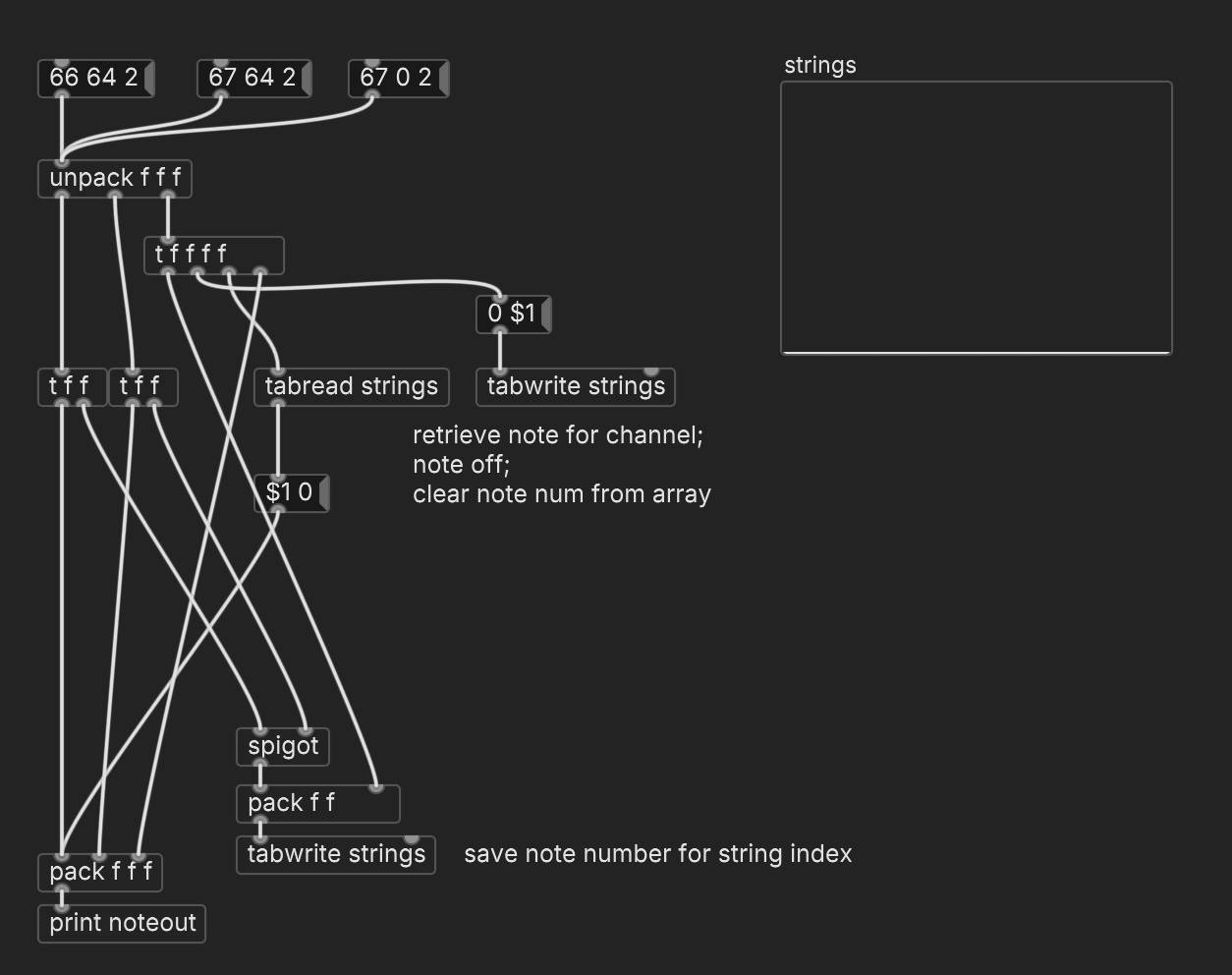
If I run the message boxes left to right, it prints:
// for 66 64 2: 0 0 2 (note-off: redundant but not harmful) 66 64 2 (ok) // for 67 64 2: 66 0 2 (note off for preceding pitch on this string, ok) 67 64 2 (ok) // for 67 0 2: 67 0 2 (ok) 67 0 2 (redundant but not harmful)hjh
-
posted in technical issues • read more
@xaverius said:
@ddw_music Thank you for your post, but I'm looking for a solution that does not influence the zoom level of other applications.
In Ubuntu, for Qt apps (which is most of them), the way to set zoom per app is to hack the desktop file:
- App menu.
- Right-click > Edit app.
- In "Command," add
env QT_SCALE_FACTOR=2before the command. (Or =1.5, or whatever.)
The problem for your case is that I don't know which graphics toolkit Purr Data is using. If it's Qt, then QT_SCALE_FACTOR in a .desktop file should work. If that doesn't work, then you'd have to find out what is Purr Data's GUI toolkit and find out how to affect application zoom in that framework.
QT_SCALE_FACTOR worked for pretty much every application I use, except Pd vanilla (Tcl/Tk), Audacity 3 (never figured out how to fix that, though Audacity 4 alpha builds are Qt-based and respond to QT_SCALE_FACTOR), and Wine (winecfg exposes a different zoom setting).
hjh
-
posted in technical issues • read more
I've long since lost the reference, but I learned a neat trick from a video once: if you need a circular buffer for a grain delay, use delwrite~ and delread4~.
You can't get a smooth circular buffer by banging control messages into a line -- well, maybe you could, but it would be delicate. You might see other tutorials that suggest running a phasor~ at
samplerate / arraysizeHz and multiplying the phasor by the array size, but floating point rounding error means you have no guarantee of touching every sample (and you still need a poke~ external that way, IIRC).But a delay line gives you the circular buffer for free. It isn't the first thing you'd think of but it is so much easier.
Pitch shifting can be done by modulating the delay time. If you're playing a 100 ms grain, run a line~ with "100, 0 100" as the delread4~ delay time and you'll get 2x speed, 2x frequencies.
hjh
-
posted in technical issues • read more
@xaverius said:
Is there a possibility to set a default zoom level for all windows that are opened? There is nothing in the preferences, but maybe a kind of config file entry?
I've just been round the bend with app zoom levels (xubuntu with Ubuntu Studio packages). XFCE does have a global zoom setting but most apps ignore it
 so I had to set environment variables. One was QT_SCALE_FACTOR; this worked for most of them. A bit of a saga, but worth it.
so I had to set environment variables. One was QT_SCALE_FACTOR; this worked for most of them. A bit of a saga, but worth it.I don't know which graphics toolkit Purr Data uses, so a Qt variable might not make a difference.
At least my experience might comfort you that you haven't missed something obvious; it's rather that HiDPI support in Linux is not quite ripe yet.
hjh
-
posted in patch~ • read more
@porres said:
how about using MPE in the sfz~ object?
")
From the first message in this thread:
There's an ongoing pull request on the sfizz .sfz player, to support MIDI Polyphonic Expression. ... So, if you're comfortable compiling software yourself, you can have fractional notes on a sample player. sfizz was a relatively painless build in Linux...
I'm pretty sure you haven't built else/sfz~ based on the MPE-capable fork (and then it would take some time for that to trickle into PlugData).
hjh
-
posted in patch~ • read more
To round out the topic, then --
The limitation in [sfz~] and [sfont~] is in the libraries on which they depend, both of which assume that they will only ever be used in MIDI-based plugins.
So I had a specific requirement, and happily got notified that someone updated sfizz to make it possible to implement using MPE -- which I did, and wanted to share the outline of the technique.
Then the suggestion that MPE might not be necessary if I had only looked deeper into ELSE and found sfz~.
But MPE is necessary for this case, to associate note-offs with the right note-ons.
(Well, it would be better if the sfizz developers had been more forward-thinking from the beginning and supported fractional note numbers -- which... it's right there in the VST3 header --
float tuning!! -- the idea that "we are only getting MIDI, so there are no fractions" is simply nonsense, hasn't been true for as long as VST has been around. But they didn't, so we have to rely on clunky workarounds. MPE is still IMO not exactly less clunky but at least possible to make it work properly.)hjh
-
posted in patch~ • read more
@porres said:
see else/width~ and else/spread~ for stereo spreading
Is
width~a recent object? I can't find it.Anyway here's a working approach, which I think uses only vanilla objects. When the incoming pitch had been steady but then changes, it should choose a new random detuning distribution. The right-hand slider changes the detuning width continuously: values around 1.02-1.04 get that Serum-y effect.
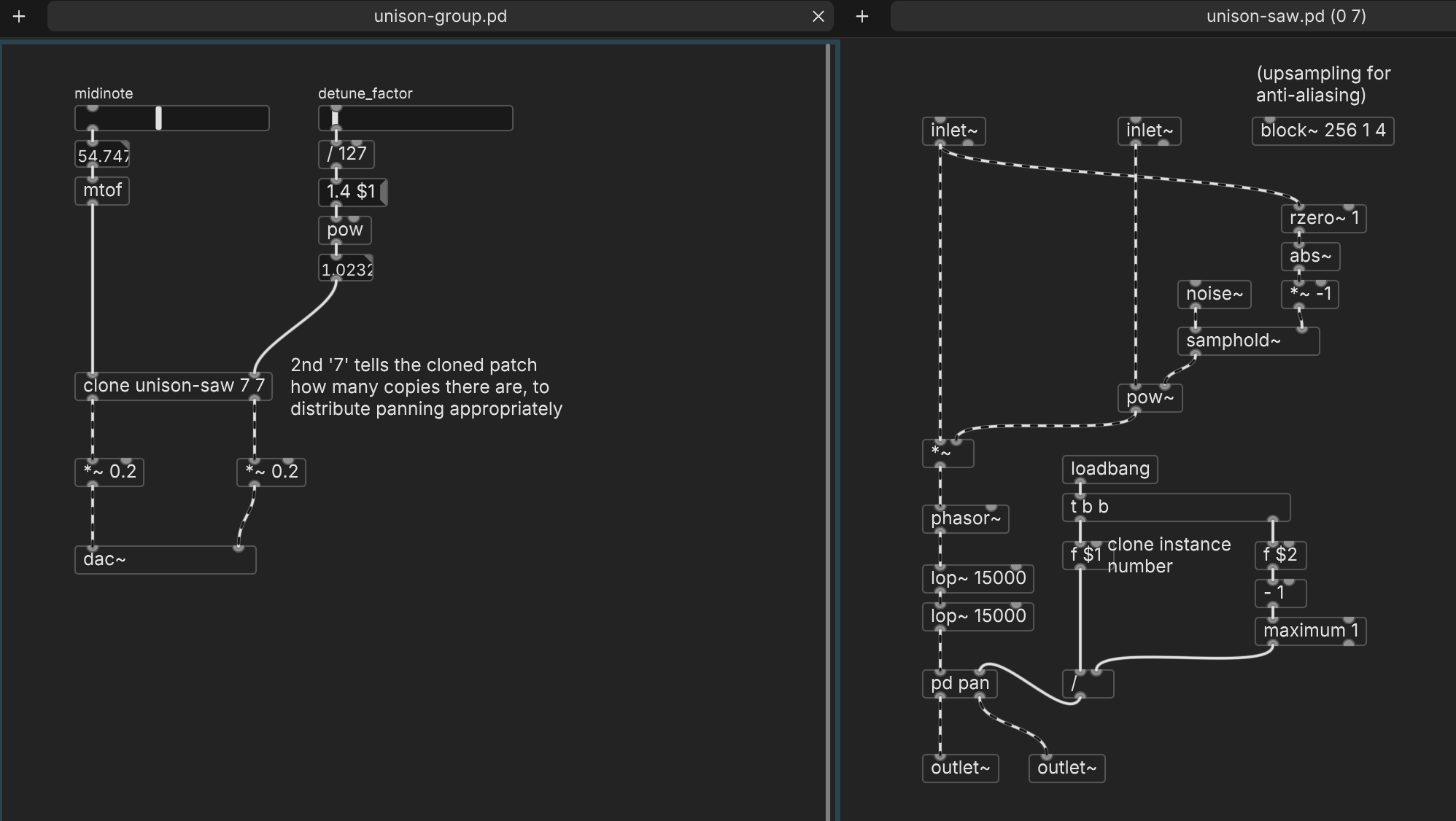
hjh