
I have a large patch that has gotten very messy because of all the lines connecting objects. I'm considering replacing most of the lines with sends. Does send have more overhead than lines?
-
Overhead of send compared to connecting with lines?
-
@jamcultur They are the same other than when the file loads, pd replaces sends and receives with wires internally. The one catch could be the increased symbol count but your sends symbols are unlikely to push that over the edge unless you are already at the edge.
Edit: Actually I don't think send symbols will affect things unless those symbols are being sent into the right inlet of the send through a symbol object or a symbol message. I am not quite clear how the symbol handling here works but I don't think there would be any reason to dump the send symbol to the hash table when that symbol is statically set as an argument to a send object and perhaps this is why we don't get a right inlet when we pass the send symbol as an argument? But probably more depth than you are looking for, I am just seeing if someone who actually knows will elucidate for me.
-
@oid said:
[...] They are the same [...]
i didn't try to check the technical details there and i certainly don't say that this is wrong - but i'm surprised anyway when comparing the two. shouldn't these give the same result then?
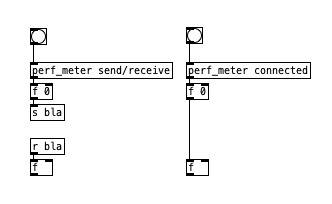
this
perf_meteris an abstraction i made to check control rate stuff by sending as many bangs as possible for ~1s and counting them (obviously the measurement itself skews the result). with this, i get:[perf_meter]: send/receive bangs time(ms) bangs/ms 12693566 1000.0 12693.57 [perf_meter]: connected bangs time(ms) bangs/ms 13707334 1000.0 13707.33... also attaching the abstraction - if you want to test or check if there is anything wrong with it: perf_meter.pd
-
@ben.wes I could easily be wrong. How it was explained to me is that they are syntactic sugar and when pd constructs the graph it replaces all sends and receives with wires so the only increased overhead is when the graph is constructed. Perhaps the graph is constructed more often than I was lead to believe? Either way I don't think I will start worrying about it but I would not mind clarification on this.
-
@oid all symbols in pd go into the hash table and never get collected.
as far as overhead goes, it does have to walk the linked list of 'things' that are attached to the symbol, and then output from their outlets rather than just outputting from the outlet directly (though, the connections also use a linked list so maybe it doesn't matter too much.. still there's an extra operation at least).
it does use slightly more memory for each object which also could influence cache misses I suppose (along with having to access memory in the symbol table more.) -
@seb-harmonik.ar Someone (I think you actually) explained that in the case of taking a symbol from a text or a list pd just passes around a pointer to that symbol's location in the text or list and skips the hashtable. Perhaps I assumed the skipping hashtable part and it does both, passes the pointer to the symbol in the text and sticks it in the hashtable. Things like this certainly suggests pd is passing a pointer. Would this be considered a bug in [text]? seems it should have no concept of a float like symbol.
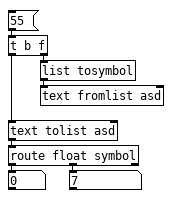
Someday I will get this sorted out, thanks again. -
@oid that's right, they don't actually have to recompute the hash function because they already have the pointer.
I guess it's more accurate to say 'having to access memory in symbols more' instead of 'having to access memory in the symbol table more'
looking at it now it also checks if the 'send' symbol has objects attached to it which is a branch so could also be slightly worse for branch prediction


