-
 whale-av
posted in technical issues • read more
whale-av
posted in technical issues • read more@le26muko Yes....... https://forum.pdpatchrepo.info/topic/788/open-a-pd-patch
That thread also tells you how to make an abstraction or a sub-patch visible, which is I think what you are asking for...?
David. -
whale-av
posted in technical issues • read more
@jamcultur Escaping the 0 seems to work, but I cannot see a way to preserve the message on reopening the patch.
This from I think @jameslo works.......... concat.zip
David.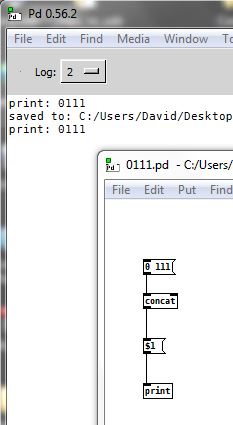
-
whale-av
posted in technical issues • read more
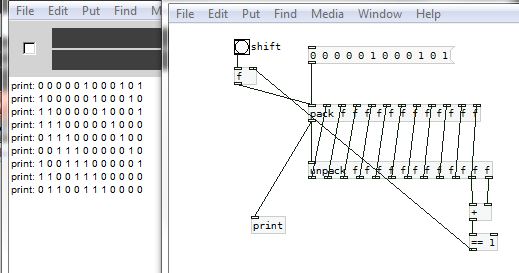
@Ice-Ice ..... from the tombs of the forum...... shift_xor.pd
Fixed length of course..
.... credit to @oid
https://forum.pdpatchrepo.info/topic/13977/rotational-shift-input-output/7
David
-
whale-av
posted in Off topic • read more
@Jake-15m3 You might find some clues here....... https://forum.pdpatchrepo.info/topic/11850/explanation-for-lop-object-in-this-patch-requested
Some discussion and maths in that thread, and links from @seb-harmonik.ar that lead to posts showing the source code for such a low pass filter.I can imagine that audio modelling could resemble fluid dynamics of an incompressible liquid so... ?
David. -
whale-av
posted in technical issues • read more
@ddw_music Well you can change the font for the patch........ change font.pd ... but it doesn't help for the console or menus.
You can also set the same for your Pd in the preferences with a startup flag...... -font-size x
Pd boxes (messages, objects) are scaled to the font but arrays and graphics are not.
And it will likely make a mess when sharing too.
There was a discussion about setting the DPI for the OS I think, and then excluding all other programs but that is probably not satisfactory either.
Of course someone might have a better solution since the last time this was asked.
Discussion found so far...... https://lists.iem.at/hyperkitty/list/pd-list@lists.iem.at/message/D7Y2HW3X3IMYEAF2N7DY5GR2T3G2A6RQ/I have noticed that sizes are sometimes different in different releases for windows so it could be worth delving deeper.
David.
P.S. just playing around with pdwindow.tcl....... I am sure it can be taken further.......

-
-
whale-av
posted in technical issues • read more
@phil12345678910 That looks like windows. The exception suggests a registry problem.
As nobody has replied and I see nothing in the Pd-list it is maybe safe to assume that you are the only one suffering.
Which version did you download and did you install it or is it the portable version.
There are still 32-bit versions on the download page...... https://puredata.info/downloads/pure-data ... and quite a few experimental versions of 56.2 at the moment.
Did you get the right one?I only have Pd-Extended actually installed.
I keep up to date in windows using the portable version (64-bit for me) and I have no problems with the current 0.56-2 second bugfix release.
Maybe try the portable version to see if you have the same problem.
You cannot start the portable version with a double-click of a patch file.... that will open the version that you have installed instead.
You have to open it (Pd) and then open the patch from the Menu open dialog in the console...
David. -
whale-av
posted in technical issues • read more
@willblackhurst Look inside [pd vu] in the [pd example] sub patch and you will see that that is where the audio signal is converted to floats using [env~]......
David. -
whale-av
posted in tutorials • read more
@willblackhurst Yes.... it does seem to have disappeared completely.... Browser independent.... just gone.
The wayback machine might find it.
I tried to explain it here in English..... https://forum.pdpatchrepo.info/topic/9774/pure-data-noob/4
A few others also contributed and it might be worth reading the whole thread from the beginning.
David. -
whale-av
posted in technical issues • read more
@willblackhurst No. It takes floats in and you need something like [env~] or [slop~] to convert (sample...) the signal to floats first.
In extended there was also a specific binary to do a tailored conversion.... [pvu~] from iemlib.
It allowed to set a release time too.... so a sort of "hold" for the meter.
David. -
whale-av
posted in technical issues • read more
@lacuna [phasor~] only resets at block boundaries..... https://forum.pdpatchrepo.info/topic/3699/phasor-with-sample-accurate-phase-reset
So this might be what you need...... vphasor~.zip
I think this was the previous discussion...... https://forum.pdpatchrepo.info/topic/12865/samphold-noise-phasor-noise-round-off-error-or/3
David. -
whale-av
posted in technical issues • read more
@fossicks Welcome to the forum...!
https://curiousart.org/digital_proj/pd_eBook.pdf
Around page 264...... especially [env~]
A great resource for working with GEM and Pd.And you might like this...... waveform-vanilla.zip
David. -
whale-av
posted in technical issues • read more
@SourRon70 Welcome to the forum.
It is difficult to diagnose problems without seeing the patch that you have created.
Would you please upload your patch to this thread using the "up arrow" symbol above where you are typing.
David. -
whale-av
posted in technical issues • read more
@y0g1 When you say "1" signal do you mean float 1?
Even with [block~ 1] you will not get the control rate data until the end of the 64 sample Pd block.
You can visualize it with an array after the fact......... a lot of discussion of samplewise stuff here......... https://forum.puredata.info/topic/13317/looking-for-velvet-noise-generator/69
and also using [print~]
Both Vanilla.No time at the moment but you could play with [env~ 2 1] which should give you the data... again after the fact.......
David. -
whale-av
posted in technical issues • read more
@nycjacqui It does look like issue 541 is your exact problem.
I think you will have to wait for the new signature, but you might be able to set your computer time to earlier (when the certificate was still valid) to do the install of a previous version. Then allow automatic time updates again but not allow Gem updates until you see the issue resolved.
But that might break other things... research it first...If you open an account with Github then you can post on the issue thread, and get email notifications when the thread is updated.
Once logged in you can also search threads...... so it is worth having an account anyway.
David. -
whale-av
posted in technical issues • read more
@dialer_vox A RPI runs Linux, and so Pure Data (and Plugdata) can be run in exactly the same way as on any Linux computer (or Windows or OSX computer).
You would probably want to run a VNC program so as to see the RPI desktop on your laptop/computer.
Or if you have a spare HDMI screen, mouse and keyboard, you can use the RPI just like your laptop while you are setting it up....But for live work you might need a better soundcard with lower latency than the built-in RPI card.
David. -
whale-av
posted in patch~ • read more
@JuanMadrid Hello. You can use the [curve~] external, or if natural curves are sufficient then square the output of [vline~]......
See this thread....... https://forum.pdpatchrepo.info/topic/9819/curved-adsr-envelope/3And yes... you cannot open that adsr object because it is not a patch. It is a compiled object like [vline~].
David. -
whale-av
posted in technical issues • read more
@nycjacqui Can time machine be used to roll back updates?
Also, what did you update first that caused the problem?
I an not using OSX but someone might have an idea.
If you can narrow down the problem you might find answers here...... https://github.com/umlaeute/Gem
And especially here.... https://github.com/umlaeute/Gem/issues/541 which is new and could get some feedback...
David. -
whale-av
posted in technical issues • read more
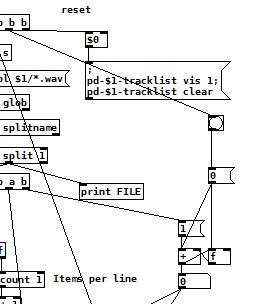
@user478 Strange. The counter doesn't increase for me. Are you sure you have not deleted a cord in the patch?
The b at the top left of this screenshot should send 0 into the counter to reset it as a new folder is loaded.....
David.