
@weightless Amazing! Great work! Thank you! ")
-
MIDI into [seq] and Markov chains
-
@ingox Thanks for mentioning this idea, turns out that starting from scratch ended up cleaner than adapting an old patch. I think it's possible to make it more useable by putting the controls in a GOP, and also we can save the source and chain texts with savestate. which is very helpful.
Now I wonder how to go about trying to make a polyphonic version. Would you mind expanding on this?
@ingox said:
To use it with polyphony (chords instead of notes) one would have to outsource the polyphony by collecting the chords in an external lookup [text] and just throw the indices into the [markov] object. So this was the reasoning behind the things i mentioned above.
Also I have a vanilla l2s and s2l, not sure who made them but they use makefilename and list tosymbol and list fromsymbol. Would you say these are still too slow for long midi files/input lists? Of course getting rid of the symbol encoding is best because it saves quite a long step, but I just don't think it's possible to do polyphony without it. Perhaps you have a workaround to it.
-
@weightless Yes, i mean like this: markov-poly.pd
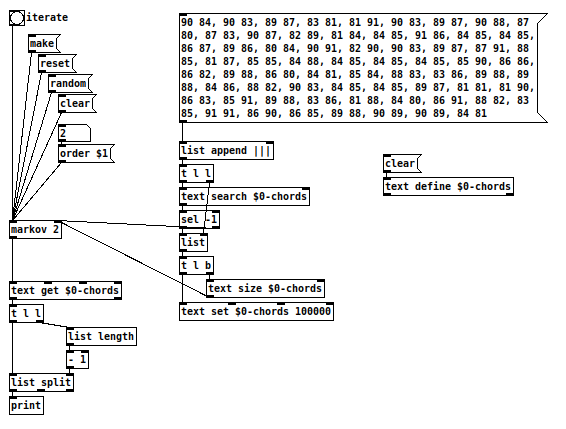
This uses your monophonic [markov] object, but keeps the polyphony outside by using a lookup table, so the chains are only build on the indices. To prevent [text search] being confused by chords of different length or single notes, i put an ending symbol after each chord, so it is unique.
Edit: A small fix. Hopefully it works now
-
The [list2symbol] abstractions are probably from this thread: https://forum.pdpatchrepo.info/topic/10556/vanilla-list2symbol-abstraction-pd-0-47/11 or they are similar. There have been some improvements, but at the time of building markovGenerator, they have been far too slow to read a long midi file in. As [seq] was used in the patch, it didn't really matter to use other externals, but for the general [markov] object, i think it is great to keep it vanilla
-
But the above polyphonic section could possibly be built into [markov] as a default, maybe it doesn't hurt too much. The only difference would be that lists would no longer be supported as inputs, as they would be regarded as chords. So lists of notes would have to be dripped from outside. I don't know what is the better or cleaner or more logical way. Anyway, everything is possible and i am quite happy that you built it, @weightless.

-
So, i incorporated the above into the object, now it is polyphonic.
I also added a [sel] shortly after [r $0-make] to protect against the source being empty. And i removed the [clip] as it was also giving problems when the source was empty, actually blocking the setting of the order. I simply replaced it with [max 1] and put in another mechanism to find the maximum order after make. It is a little bit clunky, but it seems to work for now...

-
@ingox Thanks for the patches, I understand what you mean now. This is clever, but if I got it right it means that the markov chain is either monophonic or polyphonic, it can't have a mix of both (how do you tell a single note from a chord index?). In the MarkovGenerator you'd store each event one after the other regardless of whether they are single notes or chords. I think this behaviour is desirable, or at least more flexible.
I've been thinking about this and I reckon the most logical way to approach it would be to first understand what distinguishes a "chord" from a single note, and the difference is that chord notes all happen at the same time. In Pd that's what a list does basically, and so it makes sense to me if an incoming list is interpreted as a chord. This would be the most practical approach. I went a step further and parsed the right inlet this way: lists are always interpreted as chords, a stream of floats and symbols is also interpreted as a list IF there is no delay between the elements (like in an actual midi chord), otherwise they are interpreted as single floats or symbols respectively.
Then in the memory text, only lists are joined together with [vl2s] rather than converting everything to a symbol, this is a good compromise I think. The advantage is that if you don't send any lists at all, the abstraction acts just like the monophonic version (no encoding).
polymarkov.zip
I hope everything works properly, it will require some testing. I've modified a few things including the clip problem, put everything in a gop (makes more sense than using an argument) and added state saving for the texts and order. -
@weightless I don't have the time right now to review your patch, will do that later.
Just a quick note: My proposed polyphonic [markov] above can also work monophonic, just by sending single notes instead of lists. A list is always interpreted as a chord, a single note as a single note. It works exactly like your initial proposal, only lists are not accepted as single notes anymore. So if you have a list of single notes you want to add, you would have to send it to a [list-drip] outside of [markov] and then to the right inlet. That is the only difference
")
-
@weightless Ok, i took a quick look.
At first glance, it seems a little bit too complicated, since you tread lists as chords, it seems does to do the same thing as my proposal above. So the whole delay thing would not be necessary. Maybe i am missing something.As to the GUI, i love the idea of a basic general purpose vanilla [markov] object, where everybody can add GUIs on top of that. No need to mix it in my opinion
-
@ingox Thanks for your feedback. The idea behind the delay thing is probably not necessary if you send lists manually to the abstraction, but if you use it to record some sort of live input you need a way to tell chords from single notes, I think. But that could be done externally.
I also prefer to make more general purpose abstractions generally, I just thought I'd include everything since you can't use the object without sending it make, but I see your point and agree.
I need to take a closer look to your patch again and see what I missed.
-
@ingox Yes! Now I get it, no more pd for me after 3am
The only question I have is why do you need to add ||| at the end of each item?
As for the rest I think it's the simplest method if you want a bare bone abstraction, everything else like state saving and building chords from a stream etc.. can be done outside of it.
There is one further simplification I have made which gets rid of a few objects, it's inside [pd make.markov] after text sequence. There was a leftover from the pre-list store days of MarkovGenerator.
Great work! thanks a lot -
@weightless Great!
If you have the chord 88 90 in the [text define $0-chords] and a single note 88 comes in, [text search] would only look in the first column and find the line with 88 90, where this is in fact another element.
If you add ||| or any other unique symbol to the right of each note or chord, it would be 88 90 ||| in the [text]. Now [text search] is looking for 88 ||| and cannot find the line with 88 90 |||. So each note and chord is uniquely identifiable
-
...
-
@ingox Perfect!
This is your patch with the simplification I mentioned, I also changed the text names so they make more sense (hopefully?).I'm wondering if you'd include state saving in this simple abstraction, it's basically the same as using the text define -k flag but multiple abstractions can hold unique chains.
-
@weightless I think using state saving sounds great. Can this also be disabled or otherwise controlled from the outside? I have to admit i have never looked into it
-
@ingox State saving works only if one (or more) instance of the abstraction is loaded in a parent patch. When you save the parent patch, all abstractions dump the content of their tables which get saved in the parent .pd file, each linked to the instance of the abstraction that sent it. when you re-open the parent patch, those saved tables are dumped back. Nothing is stored in the abstraction itself, so if you open the abstraction file nothing gets recalled and so the tables are initialised as empty (you mustn't use the -k flag).
I suppose it could be disabled but I can't think of any scenario where that would be advantageous.I've recently made these abstractions which I use all the time and have made my pd life so much easier I don't even remember what it was like before.
https://forum.pdpatchrepo.info/topic/12066/store-state-patch-less-state-saving-method-for-abstractions/9The only difference in our markov patch is that the order cannot be set with an argument anymore because if you create the object [markov 3], then send it the message [order 2(, and save the parent patch, the text is saved containing a second order markov chain, but when you open the parent again it loads the argument 3. In fact I think it's not ideal to set the order in the argument.
I hope this makes sense, I'll post a modified patch to show this.
-
@ingox Here it is with state saving. If you open the help patch and click the two iterate bangs you'll see that the two abstractions are saved with different chains of different orders. If there is no state to load, the order initialises to 1.
I had to change a few of things connected with the order, the most significant is that rather than automatically clipping the order according to the length of the indices text, I think it makes more sense to give an error if the input source is too short for making an nth order chain. That is, if I send [order 3( but there are only 3 lines of text, I wouldn't like the abstraction to silently make a second order chain instead.
EDIT: updated zip
-
very nice work
-
@Jona It's a very useful little abstraction, I'm trying it out with some real data to see if there are any errors still.
I had to add a receive from the stored order object before the moses for [make(, this way when re-making the chain after it has been saved in a parent patch, the number of indices is checked against the correct order that was stored.One annoying limitation of the way I've implemented state saving in these abstractions is that there is no way of keeping track of the order in which the saved parameters/arrays/texts are loaded. I have no idea how to do that reliably, otherwise it would be easier to just store and load the indices and memory texts first, then load the stored order and re-make the chain on loading.
-
@weightless Sorry for answering so late, i didn't find the time earlier.
I implemented a new system to generate the chains by simply iterating over all indices. Not sure if this is more or less efficient, but it is very simple.
Chains are build from left (oldest) to right (newest).
This system has the slight benefit that the order is not limited. An order higher than the length of the material is nonsensical and results in the original progression being played without jumps, but is not considered to be an error by this system.
I also incorporated the state saving into the object, so it doesn't rely on any other external, and made a new help file.
I used some code from weightless patch that uses code from markowGenerator. So i assume that the GPL still applies to this code. The authors can always reissue the code. @weightless, @Jona, would you agree to release the code used in this patch into the public domain?

