-
jameslo
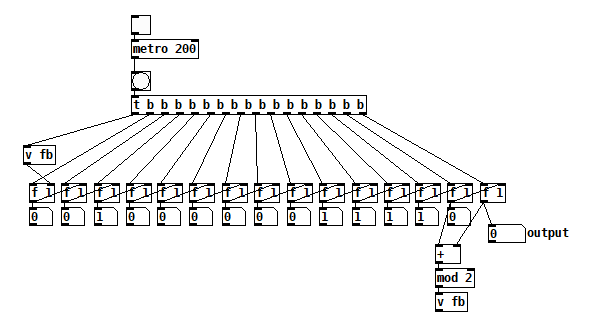
posted in technical issues • read moreSomeone on the plugdata discord asked about how to do this, but deleted their post before I could post my suggestion. I thought it was kind of fun to play with, so I'm posting it here in case you are as easily amused as I am
") I think it's interesting to watch the averaging happen as the frequency goes beyond the size of the wave table, more interesting than the interpolation.
I think it's interesting to watch the averaging happen as the frequency goes beyond the size of the wave table, more interesting than the interpolation.
one cycle of wavetable.pd
-
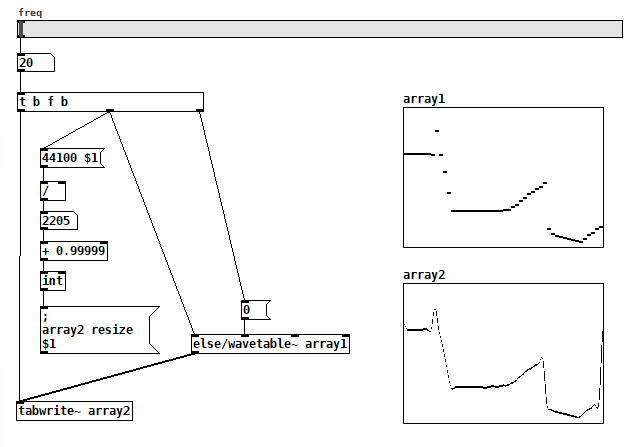
posted in technical issues • read more
@ddw_music 10 (all the way right) and 1 (all the way left).
-
posted in technical issues • read more
@kyro presented it as
input => asin => ×amount => sin~and showed it inside a larger patch: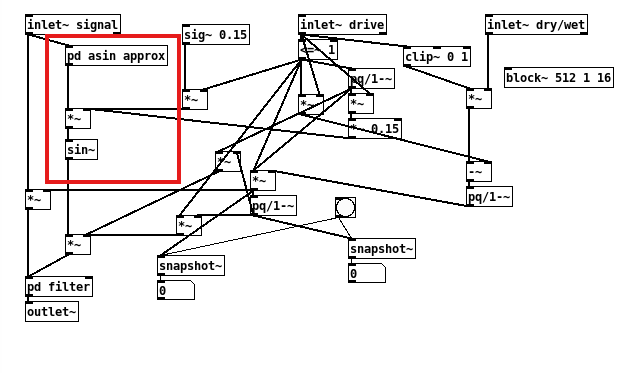
You could also adapt my [expr~] version
trig wrap wavefolder kyro version.pd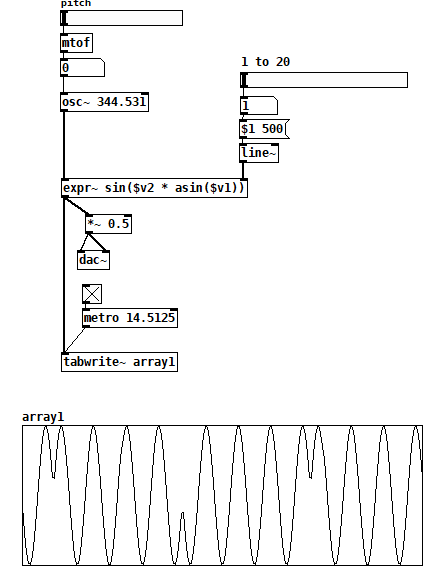
-
posted in technical issues • read more
@ddw_music Yeah, I should know better. That said, you can often click through to the sites that Google scraped and there it is!
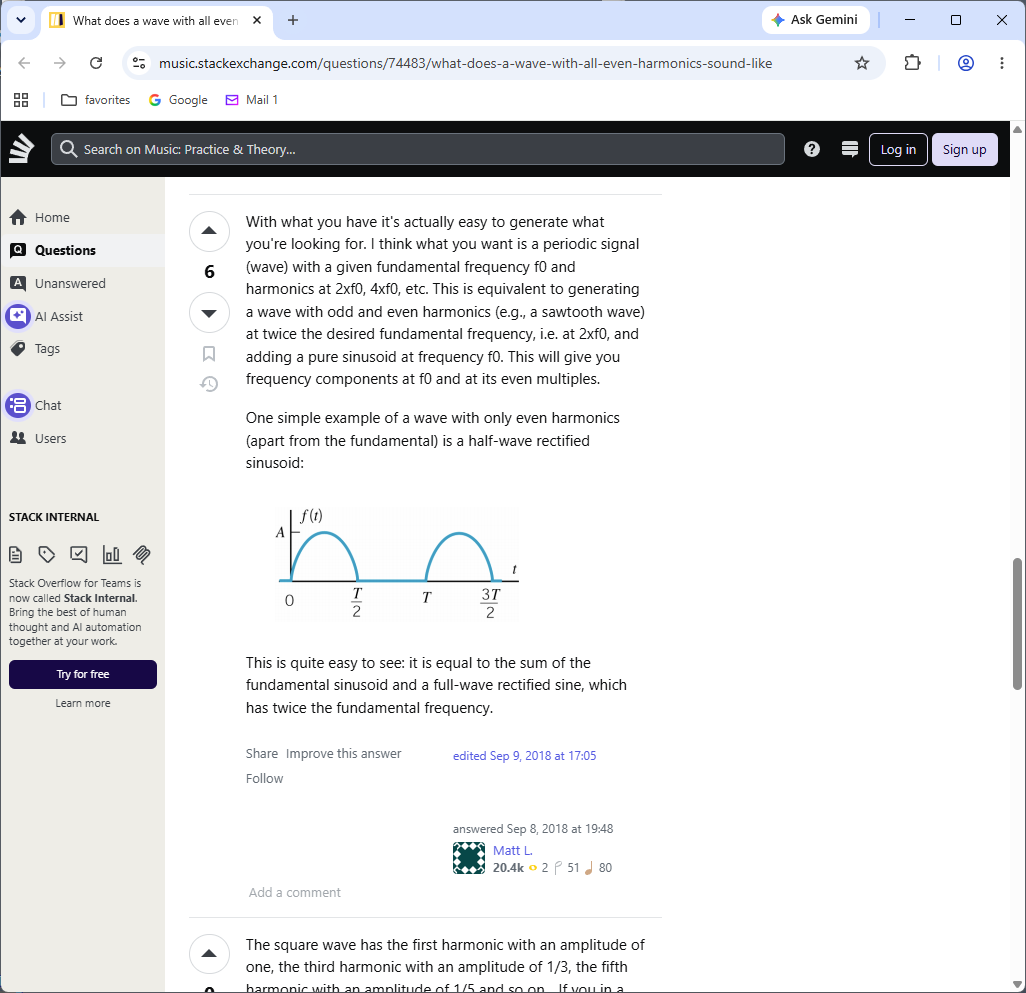
But wait! I just checked the harmonics of a full wave rectified {cos~] and all the even FFT terms have positive magnitude, so this post appears to be correct. And now I just reran my first test and set my "top only" slider to exactly 2 and am getting the fundamental + all even harmonics. Why am I getting so tripped up by this?!!! -
posted in technical issues • read more
@oid said:
Even are not emphasized in single ended, even are canceled in balanced.
This is definitely closer to what my experiment implies, thanks.
Edit: I think it's things like this that misled me in the first place--what I now believe to be false statements are highlighted in yellow:

-
posted in technical issues • read more
Look at this experiment:
symmetric vs asymmetric clipping.pd
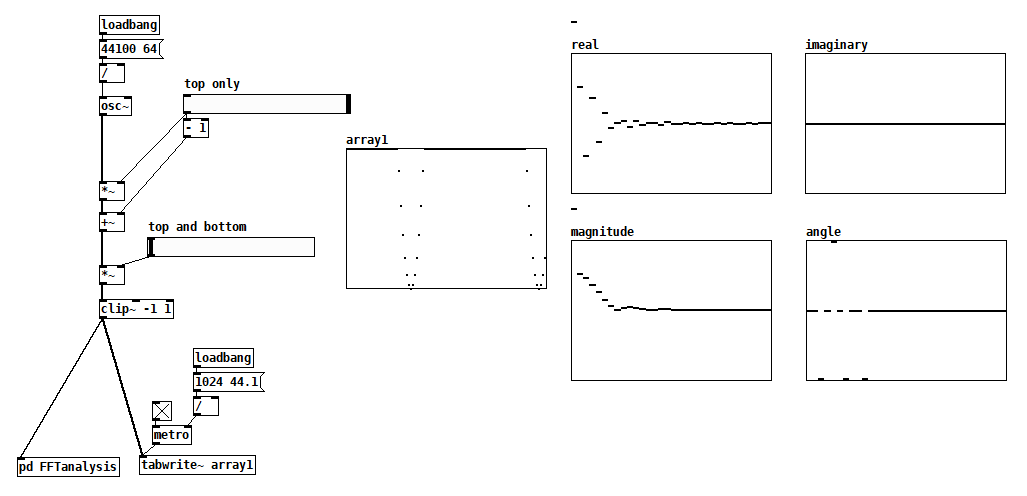
The osc~ frequency is set so that it perfectly fits a 64 sample block, which make the FFT’s terms match the harmonics of the input.When I increase the top and bottom clipping amount, the wave shape approaches a square wave and the harmonic content matches theory—all odd numbered harmonics, meaning harmonics that are odd multiples of the fundamental. Now I’ve read that even harmonics are emphasized in asymmetric signals, harmonics that are supposedly warmer and richer and are of the kind produced by single-ended tube stages, all of which have asymmetric current gain curves. That’s what my “top only” slider is crudely simulating. But the FFT contains both even and odd harmonics and there doesn’t seem to be any bias towards even harmonics, unless their mere presence is the magic sauce. What am I misunderstanding?
Edit: I was curious whether my heavy-handed asymmetric clipping was at fault, but this gentler version has similar (if not worse) characteristics.
symmetric vs asymmetric clipping 2.pd -
posted in technical issues • read more
@kyro Oh cool, I missed the fact that you could take the arcsine first, but of course now it seems completely obvious
-
posted in technical issues • read more
TBH, wavefolding interests me more for the math and programming than the sound. My first approach was to make a reflector and to put several in series:
reflector wavefolder.pd
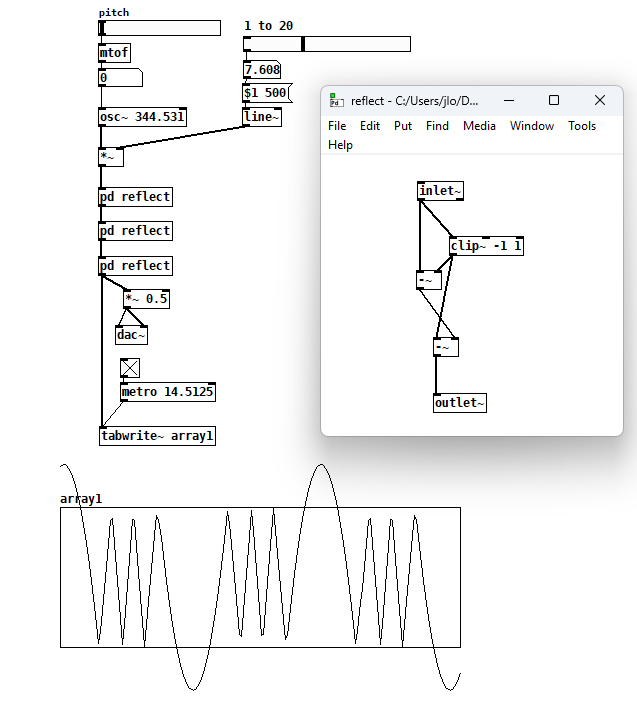
I’ve seen this kind of approach from others (e.g. using [expr~]) but it’s unsatisfying because you have to add more reflectors when you want more folds, so I came up with this next version after what felt like an eternity of head-scratching:
wrapping reflector wavefolder.pd
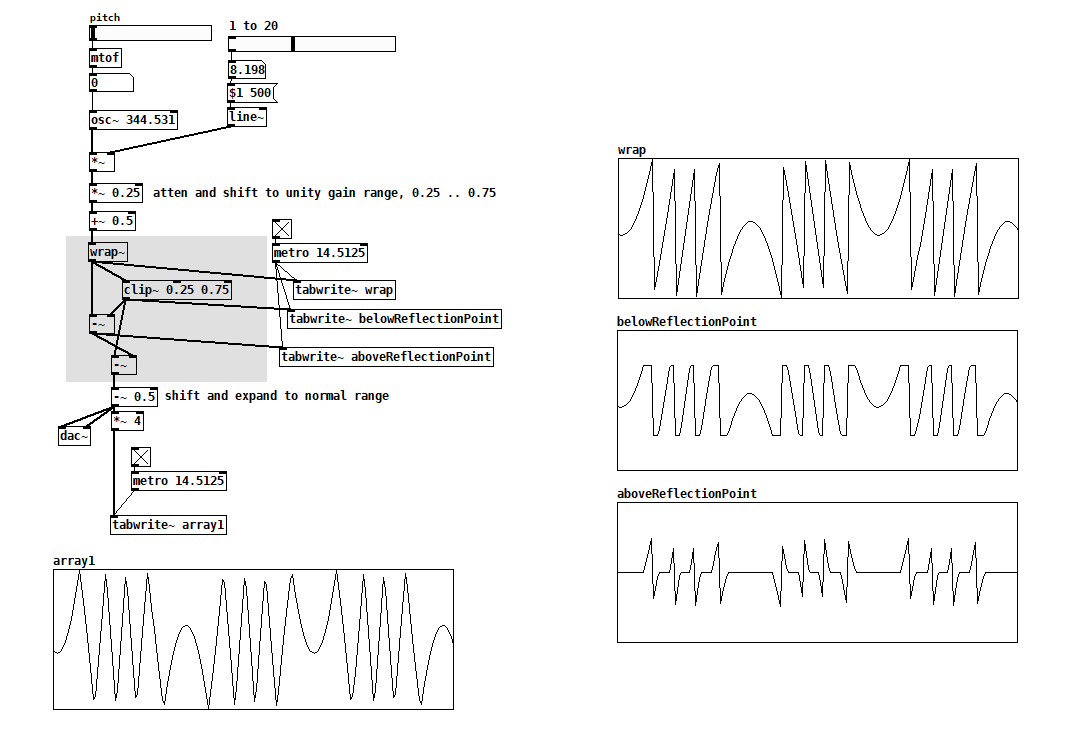
Another solution is to exploit how sine wraps around:
trig wrap wavefolder.pd
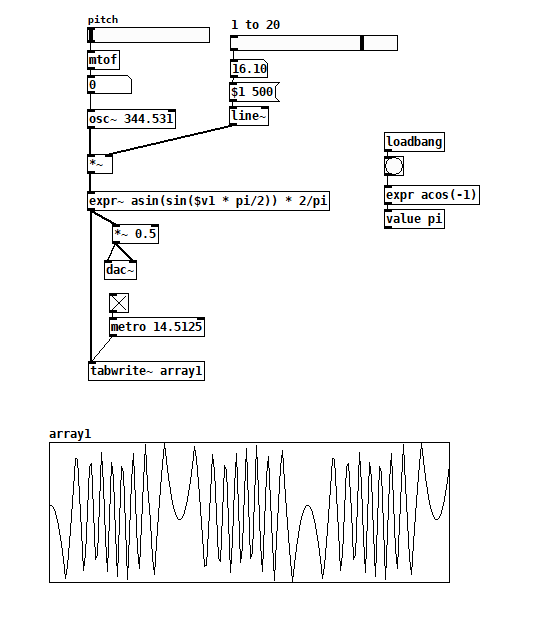
With all three versions, the sharp reversals make things very bright and can cause aliasing, which you may not be into, so I wanted to look for an alternative. Returning to how sines and cosines wrap around, I just arranged to overdrive [cos~] with my input signal:
cosine overdrive wavefolder.pd
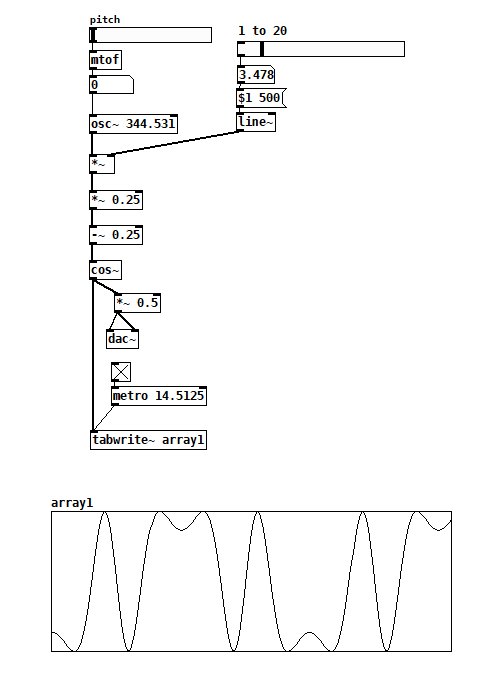
This is the version I’ve used on the few occasions I’ve thought wavefolding might sound good. The only unsatisfying thing is that it’s never possible to pass the input signal undistorted, even with folding completely off. So I thought maybe I could make a function that’s like [cos~] but linear near the x-axis. The idea comes from hi-fi tube amp design, where the designers try to scale and bias the input signal so that the tube has as linear a current response as possible. Here’s one way:
transferFunction table wavefolding.pd
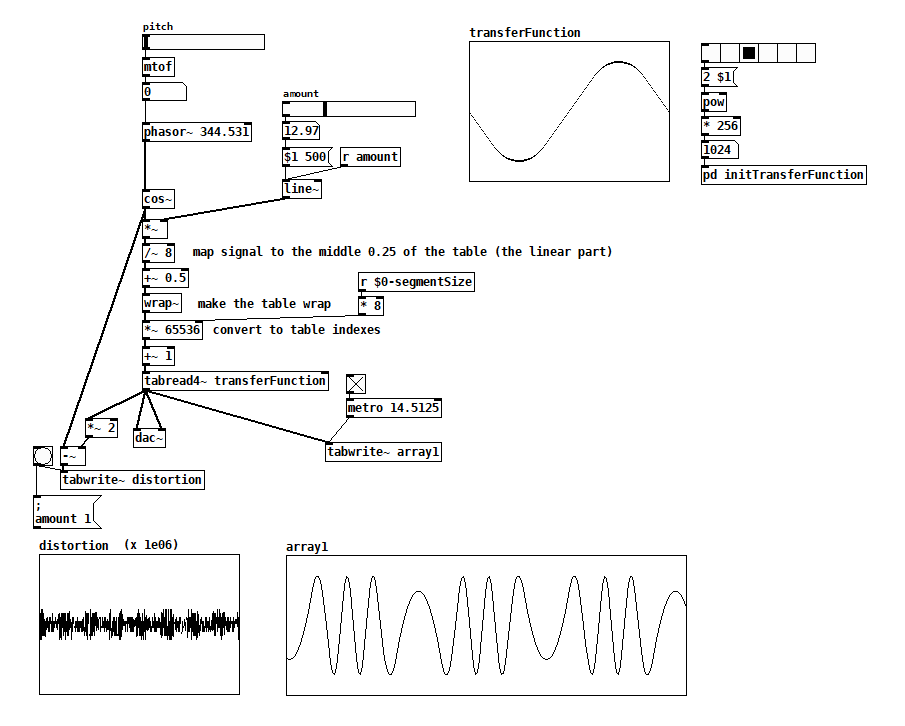
Note that you can change the non-linear part of the transferFunction table to anything you want. I made both sine and circular reversals; they sound slightly different to me. If you filled the table with a triangle wave then you’d get similar sharp reversals as in the first 2 implementations. I think that even with sine and circular reversals there are more upper partials than with the [cos~] version, so maybe another solution is just to crossfade between the [cos~] version and the clean input when you want undistorted signal.Know of other ways? Other things to consider? Have a recording that will make me love the sound of wavefolding? Please share!
-
posted in technical issues • read more
Hmm, there's something wrong with the [fexpr~] in my first post because if I trigger it on every sample (i.e. send [sig~ 1] to the [pd srNoise]), the result sounds and looks like it has a short period.
01-260606_0606.wav
Oddly, if I modify it to use the 13th and 14th taps, it sounds more like what I would expect from using the 14th and 15th taps. What am I misunderstanding/doing wrong?Edit: oh wow, check this out. When I rewrite this patch to record the value of the feedback and shift register at each step, I see that the fb is getting shifted into the register one sample late, shown here on line 14 of each array's List View.
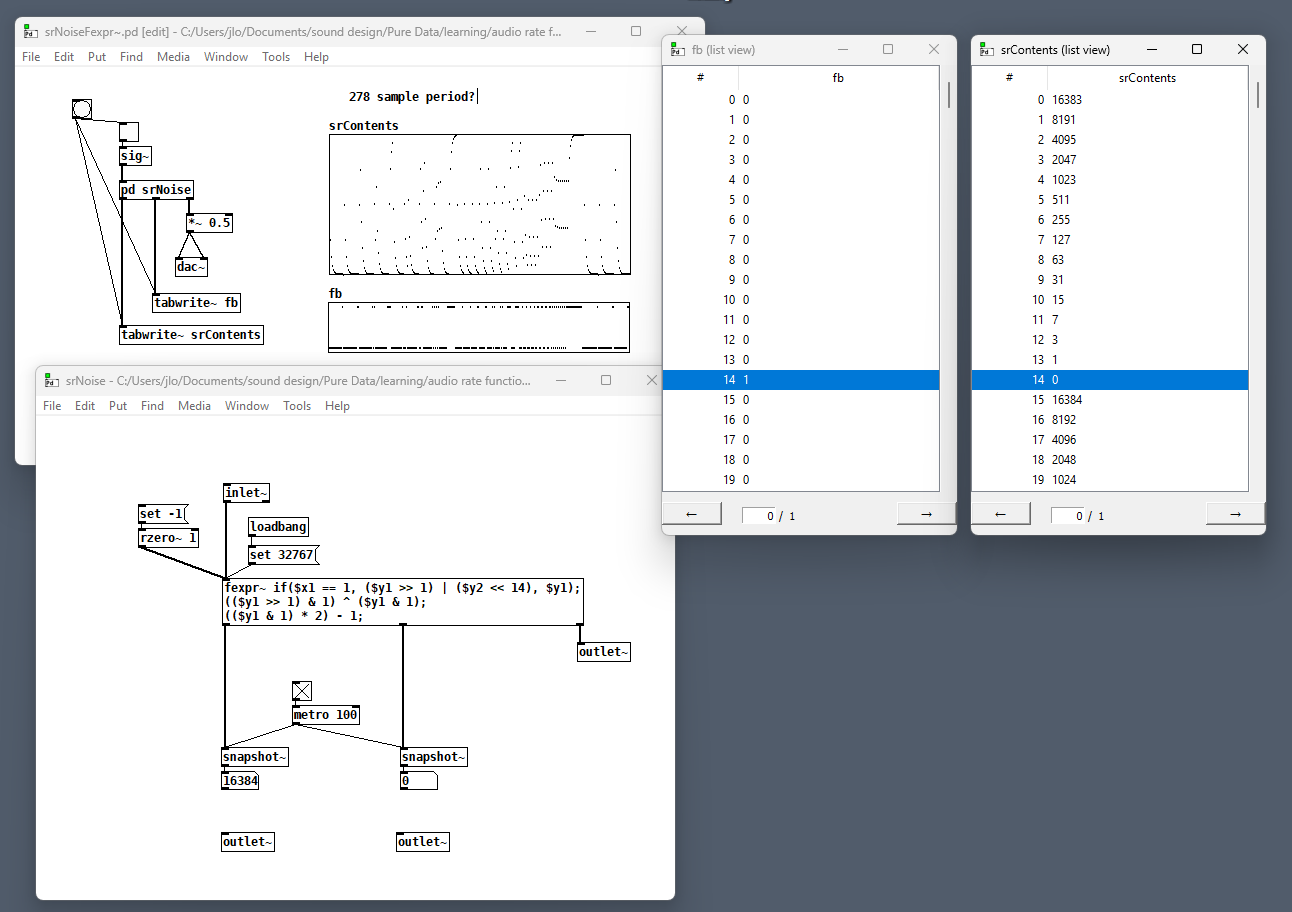
srNoiseFexpr~.pd
But when I step through the patch manually and snapshot~ those same values, the fb value is shifted into the register exactly when I expect, the equivalent of line 13. What the....?Edit 2: Oh interesting: even though $y2's output expression is evaluated before $y1's, the value of $y2[-1] is not updated until all the expressions are evaluated. Which means that Edit 2 of my first post was right but for the wrong reason. Or I could still be completely wrong.
Last edit I promise because I'm just digging myself deeper and deeper into a false statement hole: my [fexpr~] can be fixed by substituting the 2nd expression into the first, i.e.
fexpr~ if($x1 == 1, ($y1 >> 1) | (((($y1 >> 1) & 1) ^ ($y1 & 1)) << 14), $y1); (($y1 >> 1) & 1) ^ ($y1 & 1); (($y1 & 1) * 2) - 1;You can then delete the 2nd expression because it's only used for debugging. Unless someone corrects me, I still believe that output variable values like $y2 are not updated until all expressions are evaluated. I'm really not sure if it makes sense to talk about the order of expression evaluation, except for when values are referenced. So now I'll stop obsessing and will eagerly wait to be properly skooled.
-