-
-
-
 ingox
posted in technical issues • read more
ingox
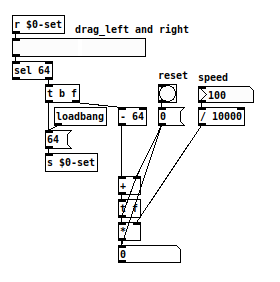
posted in technical issues • read more@oid No question. I just wanted to show this way of implementing recursion in Pd. Isn't that a technical issue?
")
-
ingox
posted in technical issues • read more
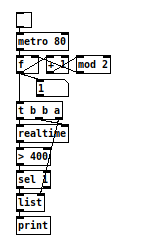
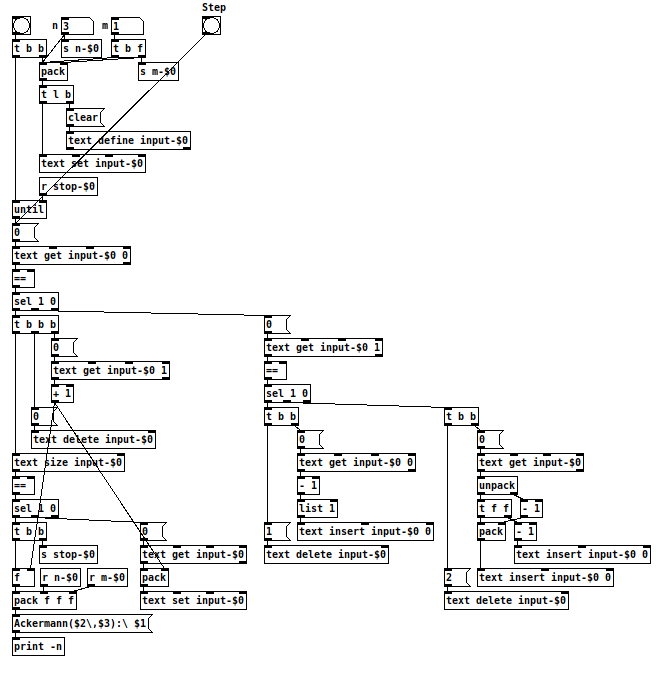
The Ackermann function is a total computable function that is not primitive recursive. That means that it will theoretically always produce a result, but it can not be reduced to a function that only uses loops instead of recursion.
The function uses very many of recursive calls and gets very large results even for rather small inputs.
In my implementation of the Ackermann function in Pd, it looks at first glance as if it would only use [until], so just a loop, and no recursion.
But really the recursion is implemented using [text], where all the incomplete intermediate results are saved until they are completed and used as inputs for the next iteration, respectively.
You can watch the process by opening the [text] and click the step button for each step of the calculation.
Be careful, while Ackermann(3,5) and Ackermann(4,0) are getting calculated quickly, it didn't finish calculating Ackermann(4,1) on my computer even after two hours.
-
ingox
posted in technical issues • read more
@esaruoho Since you already numbered the abstractions you can use [namecanvas subpatch-$1] to give them individual names. Then you can use a number to [;subpatch-%1 vis 1( to show them. I don't know if there is a way to just open an array via message. If not you can instead put a subpatch into each abstraction that only contains the array and open these with [namecanvas].
")
-
-
-
-
ingox
posted in technical issues • read more
@Buck At least you didn't burn the house, smashed the computer and moved to a hotel with a brand new laptop to find that out.
-
ingox
posted in I/O hardware diy • read more
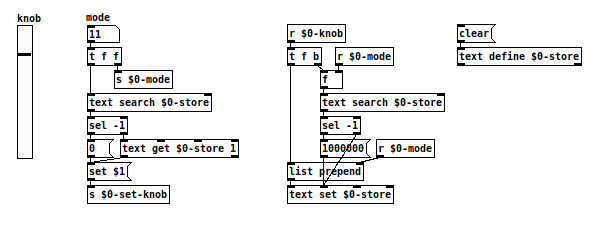
@dgbillotte It just stores each mode and respective value inside [text]. You can click on [text define] to see what is happening. When changing mode to retrieve the value and before writing, it searches for the mode in the first column if it is already there and uses the respective line to read or write. Otherwise it uses 0 as value and writes at the end of [text].
-
-
-
-
ingox
posted in technical issues • read more
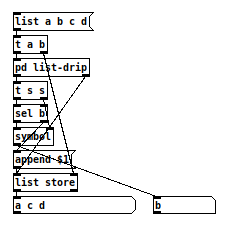
@lavirgenmarea Here is a simple solution using list-drip from https://forum.pdpatchrepo.info/topic/11122/faster-list-drip-with-list-store-pd-0-48.
[sel] is used to filter the contents. Getting the filtered element is a little bit awkward, but usually the way to go: Send the element down and let [sel] bang it through.
-
ingox
posted in technical issues • read more
@oid Thanks for testing!
I used 32 and 160 to encode $0 into the array name so different abstractions can have arrays with individual names.
-
-
ingox
posted in technical issues • read more
@oid Thanks, didn't know that. But the xy patch in the other thread still works without changes in Pd 0.52 using 32 and 160 ASCII spaces in array names and no escaping is shown.
Well, i have to say in my example the arrays are being created by dynamic patching. Renaming arrays via message works, but it will not be displayed. This is probably a bug.
-
ingox
posted in technical issues • read more
Data structure arrays have the benefit that they cannot be changed by mouse if this is wanted. So this could be nice for just displaying data.
-
ingox
posted in technical issues • read more
@yannseznec There is another method to hide the names of arrays. Rename the arrays with symbols containing only blanks. There are at least two different blank characters that can be used in Pd: ASCII decimals 32 and 160. So different names can be created by different length or different combinations of 32 and 160 blanks.
It would probably necessary to keep track of the names somehow, maybe by storing them in a list and get them by index when needed. And the patch could get somewhat un-intuitive. But it is a possible way.
If all related array objects stay unchanged, it would be enough to set them up with receives, so on load they could all receive the individual name of the according array.
The method is also described and used in this thread: https://forum.pdpatchrepo.info/topic/10854/xy-abstraction-to-get-mouse-click-and-drag-coordinates-vanilla/5
-
ingox
posted in technical issues • read more
@DespairBear A collection of dynamic patching messages: https://forum.pdpatchrepo.info/topic/10813/collection-of-pd-internal-messages-dynamic-patching.