-
ddw_music
posted in technical issues • read more@jameslo said:
But wait! I just checked the harmonics of a full wave rectified {cos~] and all the even FFT terms have positive magnitude, so this post appears to be correct. And now I just reran my first test and set my "top only" slider to exactly 2 and am getting the fundamental + all even harmonics. Why am I getting so tripped up by this?!!!
Hm, yes, the argument about double frequency does make sense. I guess neither of us considered the possibility that the initial test may have been flawed.
What actually were your settings for the two sliders in the first screenshot? I'm curious to try to reproduce it but I can't see what the numbers are.
hjh
-
posted in technical issues • read more
If it's tabwrite~ then you'd have to bang it precisely when it should loop back around to the beginning of the array. That might be doable at 48 kHz because 48000 is divisible by 64. 44.1 kHz is likely to be trickier.
For this usage, I'm a fan of count~ and poke~ in the cyclone library.
hjh
-
posted in technical issues • read more
@jameslo said:
I think it's things like this that misled me in the first place
YouTube channel House of El-AI calculates, based on Google's number of daily queries scaled down to an hour and multiplied by a ~9% hallucination rate, that Google's AI overview serves up 57 million wrong answers every hour.
hjh
-
posted in technical issues • read more
As you noted, [poly] works in the direction of note number --> channel: you give it a note number; it gives you a voice number, or channel; and then when you tell [poly] that you want to release that note number, it will retrieve the channel number.
The catch for your case seems to be "when a new note comes in to a particular channel" -- which sounds like the voice/channel assignment is happening independently of anything [poly] might do.
Does this accurately describe the messaging?
- Note on, say, f# above middle C = channel 2, note 66, velocity > 0.
- New chord overwrites all the strings, including, say g above middle C.
- g is on the high E string, so f# needs a note off: channel 2, note 66, vel = 0.
- Then note 67 gets a note-on.
Is that right?
In that case, could you not simply use an array, indexed by channel number? You have a sequential index that's coming in from outside. Arrays operate based on sequential indices. That sounds simpler to me than using a bag.
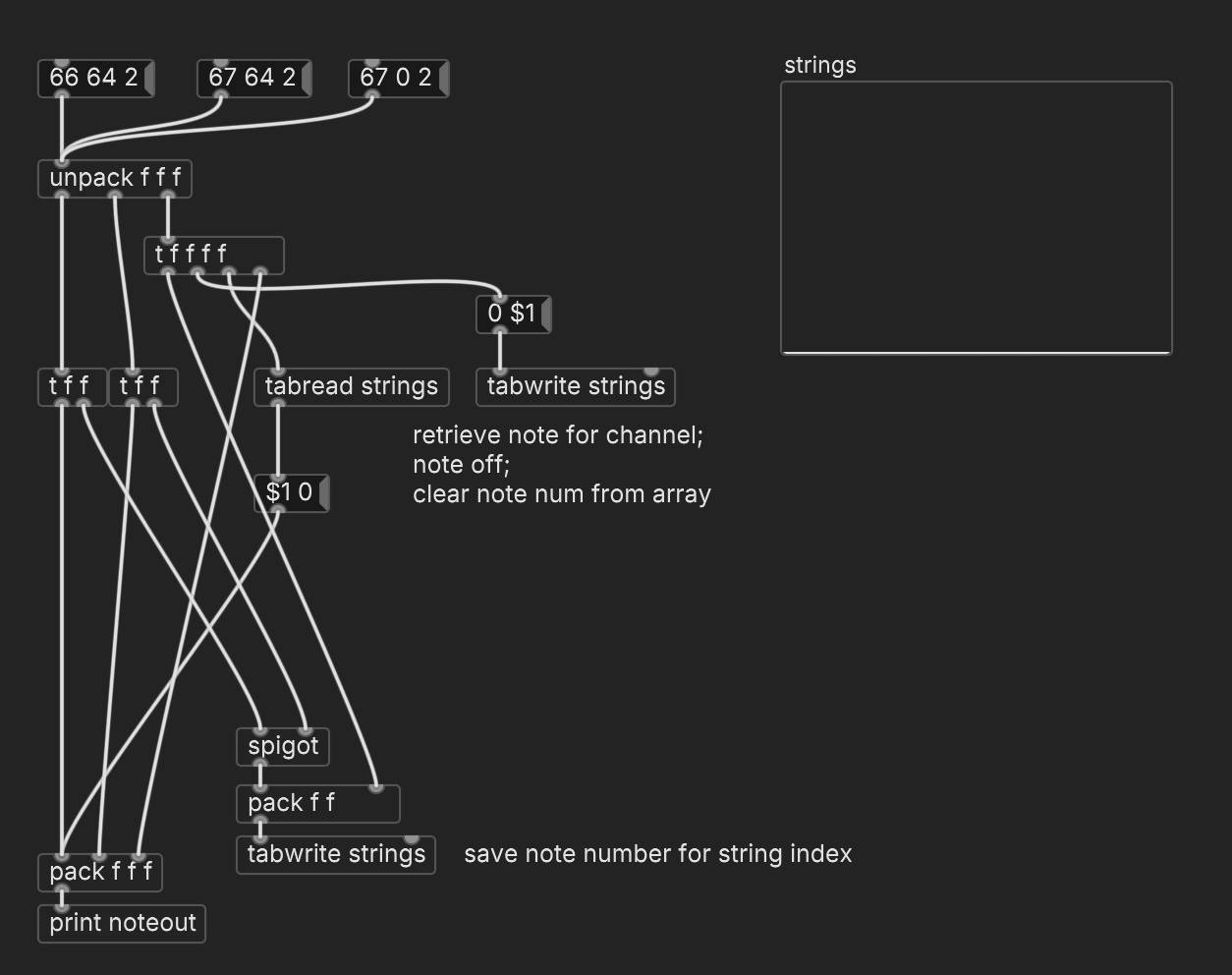
If I run the message boxes left to right, it prints:
// for 66 64 2: 0 0 2 (note-off: redundant but not harmful) 66 64 2 (ok) // for 67 64 2: 66 0 2 (note off for preceding pitch on this string, ok) 67 64 2 (ok) // for 67 0 2: 67 0 2 (ok) 67 0 2 (redundant but not harmful)hjh
-
posted in technical issues • read more
@xaverius said:
@ddw_music Thank you for your post, but I'm looking for a solution that does not influence the zoom level of other applications.
In Ubuntu, for Qt apps (which is most of them), the way to set zoom per app is to hack the desktop file:
- App menu.
- Right-click > Edit app.
- In "Command," add
env QT_SCALE_FACTOR=2before the command. (Or =1.5, or whatever.)
The problem for your case is that I don't know which graphics toolkit Purr Data is using. If it's Qt, then QT_SCALE_FACTOR in a .desktop file should work. If that doesn't work, then you'd have to find out what is Purr Data's GUI toolkit and find out how to affect application zoom in that framework.
QT_SCALE_FACTOR worked for pretty much every application I use, except Pd vanilla (Tcl/Tk), Audacity 3 (never figured out how to fix that, though Audacity 4 alpha builds are Qt-based and respond to QT_SCALE_FACTOR), and Wine (winecfg exposes a different zoom setting).
hjh
-
posted in technical issues • read more
I've long since lost the reference, but I learned a neat trick from a video once: if you need a circular buffer for a grain delay, use delwrite~ and delread4~.
You can't get a smooth circular buffer by banging control messages into a line -- well, maybe you could, but it would be delicate. You might see other tutorials that suggest running a phasor~ at
samplerate / arraysizeHz and multiplying the phasor by the array size, but floating point rounding error means you have no guarantee of touching every sample (and you still need a poke~ external that way, IIRC).But a delay line gives you the circular buffer for free. It isn't the first thing you'd think of but it is so much easier.
Pitch shifting can be done by modulating the delay time. If you're playing a 100 ms grain, run a line~ with "100, 0 100" as the delread4~ delay time and you'll get 2x speed, 2x frequencies.
hjh
-
posted in technical issues • read more
@xaverius said:
Is there a possibility to set a default zoom level for all windows that are opened? There is nothing in the preferences, but maybe a kind of config file entry?
I've just been round the bend with app zoom levels (xubuntu with Ubuntu Studio packages). XFCE does have a global zoom setting but most apps ignore it
 so I had to set environment variables. One was QT_SCALE_FACTOR; this worked for most of them. A bit of a saga, but worth it.
so I had to set environment variables. One was QT_SCALE_FACTOR; this worked for most of them. A bit of a saga, but worth it.I don't know which graphics toolkit Purr Data uses, so a Qt variable might not make a difference.
At least my experience might comfort you that you haven't missed something obvious; it's rather that HiDPI support in Linux is not quite ripe yet.
hjh
-
posted in patch~ • read more
@porres said:
how about using MPE in the sfz~ object?
")
From the first message in this thread:
There's an ongoing pull request on the sfizz .sfz player, to support MIDI Polyphonic Expression. ... So, if you're comfortable compiling software yourself, you can have fractional notes on a sample player. sfizz was a relatively painless build in Linux...
I'm pretty sure you haven't built else/sfz~ based on the MPE-capable fork (and then it would take some time for that to trickle into PlugData).
hjh
-
posted in patch~ • read more
To round out the topic, then --
The limitation in [sfz~] and [sfont~] is in the libraries on which they depend, both of which assume that they will only ever be used in MIDI-based plugins.
So I had a specific requirement, and happily got notified that someone updated sfizz to make it possible to implement using MPE -- which I did, and wanted to share the outline of the technique.
Then the suggestion that MPE might not be necessary if I had only looked deeper into ELSE and found sfz~.
But MPE is necessary for this case, to associate note-offs with the right note-ons.
(Well, it would be better if the sfizz developers had been more forward-thinking from the beginning and supported fractional note numbers -- which... it's right there in the VST3 header --
float tuning!! -- the idea that "we are only getting MIDI, so there are no fractions" is simply nonsense, hasn't been true for as long as VST has been around. But they didn't, so we have to rely on clunky workarounds. MPE is still IMO not exactly less clunky but at least possible to make it work properly.)hjh
-
posted in patch~ • read more
@porres said:
see else/width~ and else/spread~ for stereo spreading
Is
width~a recent object? I can't find it.Anyway here's a working approach, which I think uses only vanilla objects. When the incoming pitch had been steady but then changes, it should choose a new random detuning distribution. The right-hand slider changes the detuning width continuously: values around 1.02-1.04 get that Serum-y effect.
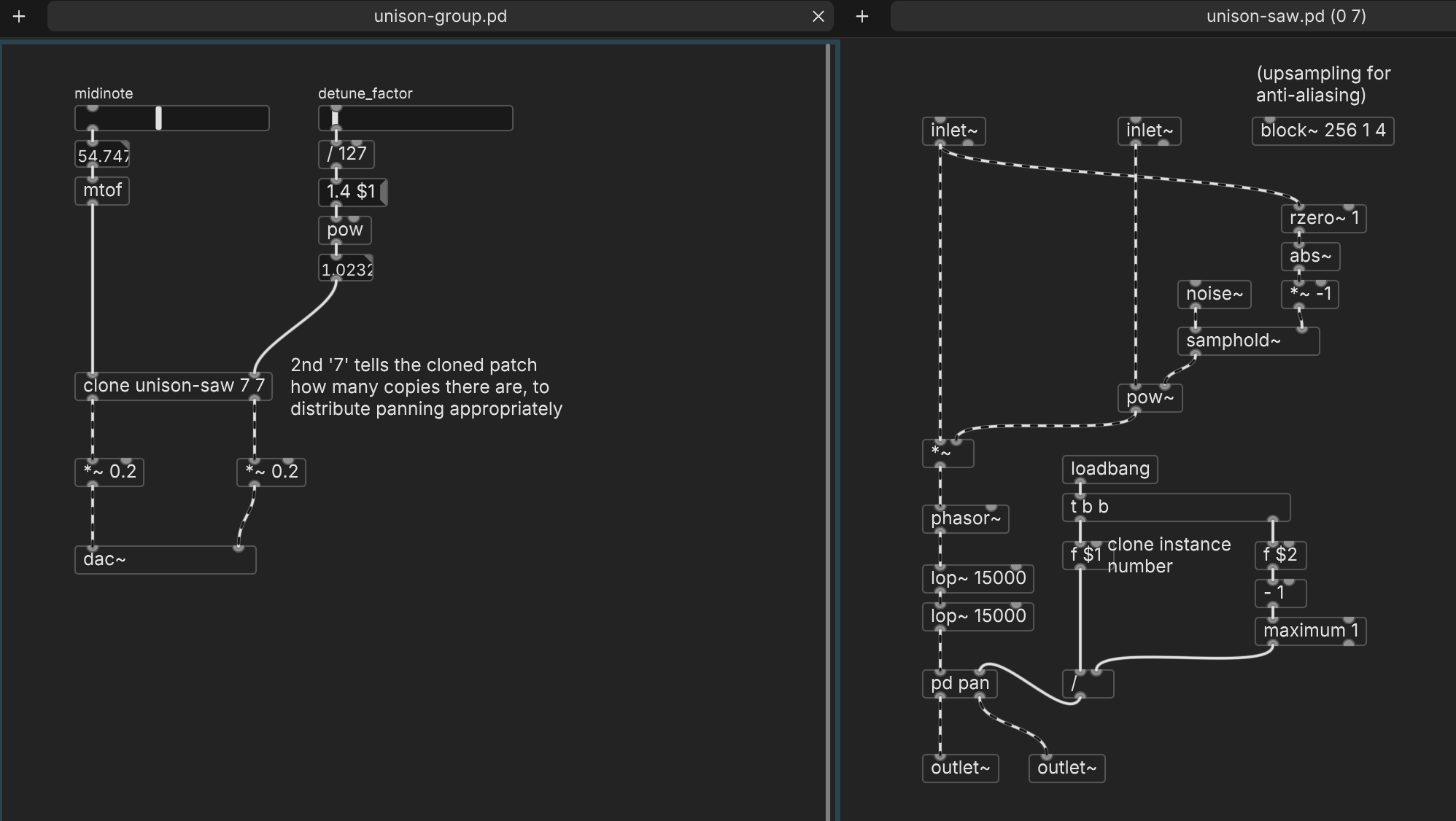
hjh
-
posted in patch~ • read more
@porres said:
I thought you wanted particular scales, like 8th tones
My real interest in this is (cheap[1]) just intonation, where both the Pythagorean and the harmonic-series major third enter into it (separated by a syntonic comma). If you'll need to use the pure third in one context and the Pythagorean third in another, then you don't want to reconfigure the instrument's overall tuning midstream; you just want to apply a fractional offset to a note, and be done with it.
There is one other problem, though: with fractional MIDI notes, you may need two or more voices playing different C naturals. Then, which voice should a note-off target? I predict confusion, for instruments like the else samplers, which truncate or round the note number. MPE disambiguates it by addressing channel numbers. So I'd guess that else/sfz~ would have trouble with the microtonal clusters in the little video (as, for that matter, did vanilla's [poly]). So the MPE way is more robust in this aspect.
Come to think of it... why does else/sfz~ truncate note numbers? You're not bound by the limits of the MIDI protocol; why not fully support fractional note numbers? (I guess it's because of a dependency on a sfz library that is stuck in the 80s/90s.)
hjh
[1] There's a neat little paper in Music Theory Online (can't find the reference now) that gives one approach to generating 5-limit JI scales: starting on, say, F, go up by pure 5ths, except every fourth step, adjust the 5th downward by a syntonic comma. Assuming C as the root and applying octave corrections, you'd get F = 2/3 (4/3), C = 1, G = 3/2, D = 9/8, A = 27/16 * 80/81 = 5/3 (pure m6 vs C), E = 5/4, etc with the next comma correction at C#. Doing this on C gives you another variant, as do G and D, completing the set of distinct scales. (The 5th one would start on A and comma-correct on C# and F, which IIRC would replicate the F scale a comma higher, so the author didn't consider that to be distinct.) The right one of these 4 scales can be chosen for different harmony contexts.
Thinking of microtones in terms of applying a single scale to the whole instrument excludes this type of approach. That is, I wasn't ignoring support for scales, but rather, I was deliberately not interested in that.
-
posted in patch~ • read more
@porres said:
else/sfz~ has support for mictrotones
What I'm describing here is a way to do microtuning without setting a scale on the player.
Or perhaps I'm just misled by the tuning page's prominent comment about using scales, where
transpmight be the droid I'm looking for.This seems to work (didn't try sfont~ this way though).
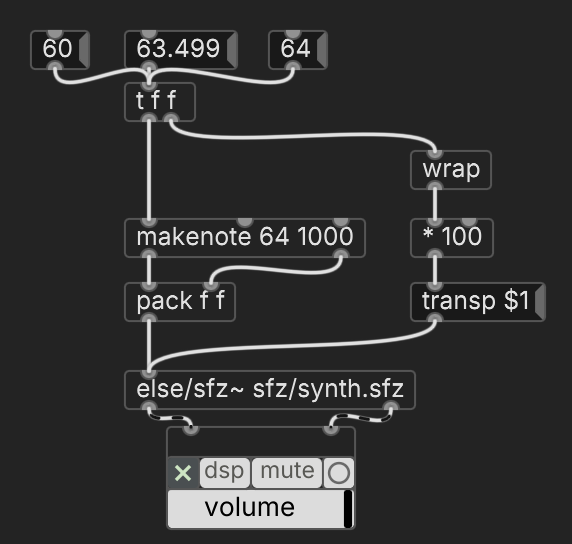
(It sounds like a transposition message doesn't affect the pitch of previously played notes -- unlike MIDI pitch bend, which is why MPE needs to split up notes among channels. If so, then
transpis more convenient than what I did.)hjh
-
posted in technical issues • read more
@solipp said:
And changing the font size doesn’t help?
Ah, actually it does. An earlier comment said "chang[ing] the font for the patch... doesn't help for the console or menus" so tbh I didn't investigate font settings further... but it does help for those.
If I set font size = 16, it's pretty close. Acceptable. Thanks!
hjh
-
posted in technical issues • read more
@whale-av said:
Well you can change the font for the patch... but it doesn't help for the console or menus.
@solipp said:
you can compile pd with this PR: https://github.com/pure-data/pure-data/pull/1659
... (where the PR implements scroll wheel zooming, which affects patch contents, but not menu bars, or the console).
Appreciate the effort, but it has to be admitted that neither of these is a full solution.
Here, I've screenshotted what I'm seeing, and scaled it down so that lower DPI screens will see basically what I'm seeing.
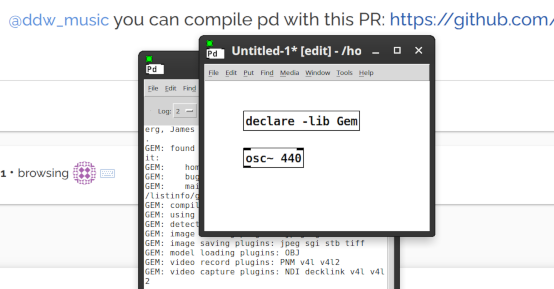
Sure. You can interact with objects. But, anything that requires a menu or a dialog box, you'd better take off your glasses, get right up to the screen, and squint. In the Windows screenshot above, menus look normal size and everything else looks big. That isn't at all what you see on a high(er) DPI monitor (2880 x 1800 here). If I zoom in on a patch, I see normal-size objects and teeny tiny menus.
I found where pd-gui.tcl says:
# we are not using Tk scaling, so fix it to 1 on all platforms. This # guarantees that patches will be pixel-exact on every platform # 2013.07.19 msp - trying without this to see what breaks - it's having # deleterious effects on dialog window font sizes. # tk scaling 1... and I tried enabling
tk scaling 2, but no effect after recompiling.There was a discussion about setting the DPI for the OS I think, and then excluding all other programs but that is probably not satisfactory either.
If I understand your meaning here, that's what I've been doing for a long time -- setting lower resolution and making every application fuzzier, just so that Pd is usable. I'd kinda like to try maximum sharpness for awhile, see how it goes.
My laptop is IIRC 3.5 years old, and it's not a super expensive one (integrated Intel graphics, pretty standard). Again, I'm fine to use plugdata for most cases -- just observing that Pd vanilla is slipping further and further behind modern hardware.
hjh
-
posted in technical issues • read more
I should also have said that I'm on Linux (Ubuntu Studio 24.04 [will upgrade over the summer probably], with the XFCE desktop).
Tcl/Tk, I suppose, will never catch up to the modern world.
When I need Pd, I mostly use plugdata anyway (I disagree with Pd's remaining tied to an outdated graphics library, so this is me "voting with my feet"). That's fine with me actually, though Gem doesn't run smoothly in plugdata. So it's not a big deal for me, but, nags at me a bit that one venerable tool can't be easily brought up to speed.
hjh
-
posted in technical issues • read more
On a high DPI display, Pd's windows, fonts, menus, etc. are stupidly small.
"It's a Tcl/Tk problem" but I just wonder if anyone on this forum found a solution for Pd?
Thanks,
hjh -
posted in patch~ • read more
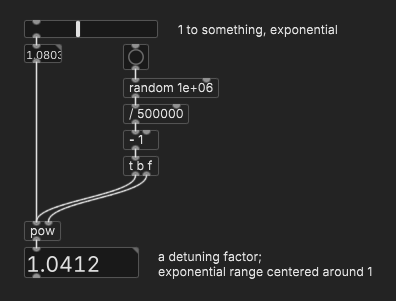
If you do this several times, you'll get a set of detuning factors centered around 1. Moving the slider expands or narrows the range but preserves the relationships between the detuning factors.
Or, better, put this into your single-voice patch, and [clone] it.
BTW probably you didn't get an answer because this is more of a technical question, where the "patch" category is for finished patches or demos.
hjh
-
posted in patch~ • read more
I like microtuned pianos, but they're hard to do.
There's an ongoing pull request on the sfizz .sfz player, to support MIDI Polyphonic Expression. One feature of MPE is that you can convert fractional values into an integer note value plus pitch bend. Since each note plays on its own channel, pitch-bend applies per note rather than globally. (sfizz also supports Scala files, but this is different -- it lets you go full Jacob Collier on your sub-sub-sub-semitones. MPE's default settings allow for 1/170th of a semitone pitch resolution.) sfizz works a treat with spacechild1's fantastic vstplugin~ external.
So, if you're comfortable compiling software yourself, you can have fractional notes on a sample player. sfizz was a relatively painless build in Linux. "git clone --recursive" from https://github.com/rullopat/sfizz-ui .
Here's what might have happened if Ligeti had an eighth-tone piano:
Initially, I had tried to use [poly] for voice/channel assignment. It got confused about so many notes so close together, so I ended up making my own version that binds the note number to the channel and duration.
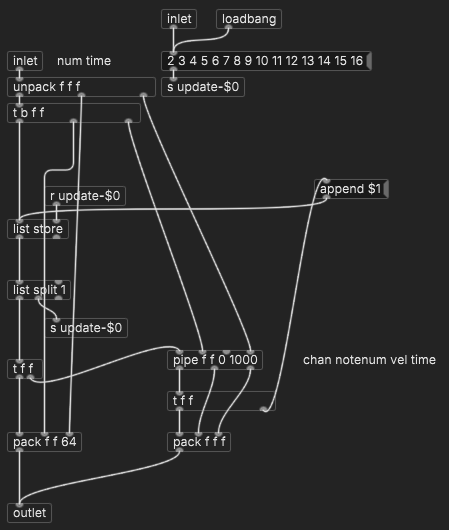
hjh
-
posted in technical issues • read more
The IAC bus shouldn't be the problem here. To explain why, it's helpful to understand what the status byte is.
In a MIDI message, thestatus byte differentiates the various message types, with a leading 1 to indicate that it's a status byte, a 3-bit code for the message type and, for messages that apply to channels, a 4-bit channel code, packed together into one byte.
Binary 1 001 zzzz = hexadecimal 0x9z = note on
Binary 1 000 xxxx = hex 0x8z = note off
Etc (https://www.recordingblogs.com/wiki/status-byte-of-a-midi-message)Note on messages on channel 1 should be encoded as 0x90 (decimal 144), on channel 2 as 0x91 (145), up to 0x9F (159) for channel 16.
So the MIDI channel information that pd receives is encoded into the message contents. The IAC bus, of course, shouldn't modify message contents! So the IAC bus is vanishingly unlikely as the cause of the problem.
Bitwig is responsible for encoding its outgoing MIDI messages, so if a wrong channel is being encoded, that's where it's happening. I'd suggest to doublecheck the outgoing MIDI channel assignment in the MIDI tracks in Bitwig. Also, in some DAWs, MIDI notes can have their own MIDI channel data; the track-level MIDI channel setting might override the note-level setting, or vice versa. You'd have to check documentation on that.
hjh
-
posted in technical issues • read more
@playinmyblues said:
If I arm any of the other tracks, I get a flashing quickly MIDI notes and then a PortMIDI: 'Buffer overflow' as shown in the jpeg.
By "arm," do you mean enable MIDI input on the Bitwig tracks?
If you're sending MIDI out from Bitwig, there shouldn't be any need to arm anything.
I'm guessing that you've got a MIDI feedback loop somewhere. For the Pd patch, MIDI should be traveling in only one direction: DAW --> IAC bus --> Pd. This Pd patch isn't sending MIDI out anywhere, so Pd can't be the source of the loop.
"PortMIDI: Buffer overflow" isn't a Pd internal error so you'll have to address it in the way MIDI is configured in your system (DAW and OS settings).
hjh