
@jancsika okay, thanks for the clarification ( i am quite new to those terms).
-
Dictionary object in pd-extended?
-
@jancsika i have to admit the data structure array attempt sounds very interesting, but i think it could be quite complicated?
somehow it seems also possible to use data structures with [text search] and other [text] objects (at least you can set a struct flag), but i have not seen any examples yet. but it is possible to use and manipulate data structure arrays with [array] (with an -s flag and the data structure array pointer).
perhaps your idea with the [symhash] object would be the easiest solution for a hash map dictionary?
and i wonder if text [text search] does use kind of a hash function? at least it is faster than sequence and get.
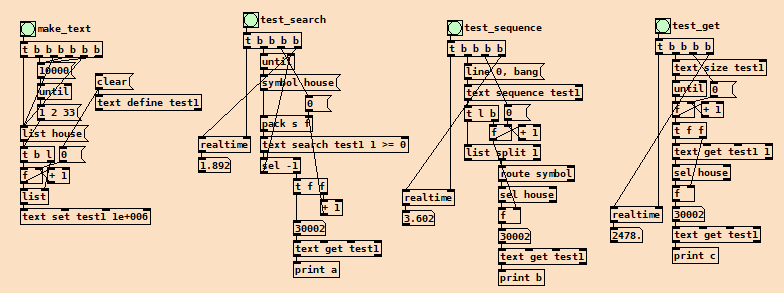
here is a small test. it searches for the symbol house in a text with 30003 lists: searchtest.pd
as part of a ofelia lua script i used another dictionary with pure data (i copied the code from somewhere without totally understanding it, but it worked):; -- make dictionary; ; local function defaultdict(default_value_factory); ; local t = {}; local metatable = {}; metatable.__index = function(t, key); if not rawget(t, key) then; rawset(t, key, default_value_factory(key)); end; return rawget(t, key); end; return setmetatable(t, metatable); end; ; -
@Jona 1.82 ms isn't fast enough for realtime. That's well over the budget for a single block at Pd's default sample rate.
[text search]is almost certainly doing a linear search through each line to get that kind of result.I'll see if I can throw together an example later.
-
Sorry, but a segfault with data structures prevents me from implementing a demo.
However, to hash a 4 character string in a Pd patch (using the same method that Pd uses internally for symbol lookup), the worst case realtime performance I measured is 0.088. That hash is then used as an array index to get a pointer to the correct text. Then it's just
[text search]and[text get], where the average search length will be 5 instead of 5000.Looking at your realtime result for
[text search], it seems likely that a search among 5 or 10 lines is going to be performant enough to calculate easily in realtime. (Although I guess there's still a rather unlikely possibility that all the values get stored at the same exact index. I don't know how to calculate that probability, but it seems extremely unlikely on the face of it.)Edit: here's a quick example of the hashing algorithm implemented in Pd. Would be a lot faster in C without Pd's message passing.
Another edit: This isn't quite the same as the internal algorithm because I'm serializing the string backwards. (For a robust implementation you'd want to use [list-drip] to avoid stack overflows.)
-
@jancsika that looks like it could be a good optimization
") using list-drip (with list-store) instead should not be the problem.
using list-drip (with list-store) instead should not be the problem. -
Hopefully this will shed some light on what I've been talking about:
dictionary.pd
dictionary-help.pdA few things to notice:
- Search performance should be at least 10x faster than the worst case for
[text search] - The total computation time for
[dictionary]should be vastly more predictable than[text search].
However, there's still a clear bottleneck in this abstraction-- calculating the hash. Not sure whether it's the conversion from symbol to list or the recursive addition, but it is slow. So slow that if you reimplement it in C as I did to test, you get another 10x speed increase.
So exposing the (C level) symbol hashing to the user and wrapping it in an abstraction as I've done should give you a 100x speedup over the worst case linear lookup time in your patch above with 10,000 items.
A more dramatic restatement of that-- since memory is cheap, this means you can create a much larger hashmap and handle an enormous number key/value pairs for realtime computation that would not be possible with linear lookup times of [text].
Edit: the abstraction is just a demo. It will happily duplicate keys (preventable by adding a
[text search]in the right object chain), and provides no mechanism to delete entries. While lookup is tweaked for realtime performance, adding keys will cause intermittent memory allocation.Edit2: This is basically the way
t_symbol *gensym(char*)works in the Pd code. It hashes the string to get the array index, then searches through the linked list of symbols at that index for the string. If it finds it it returns the memory address; if not, it creates a new entry and returns that address. That's why you can compare two symbols in Pd source code with "==" sign-- if they're both at the same address then it's the same string. - Search performance should be at least 10x faster than the worst case for
-
@jancsika thanks a lot for the demo, very nice. yes, i think it shed some light on data structures, hash maps and also how pd internally works. i did not know that text can be an element of data structure arrays.
i tried to implement the text search at the right object chain.
to save the patch i need to clear $0-data first, otherwise the patch crashes before saving.
interesting that the hash conversion is a bottleneck, without it is 2 times faster (in pure data).
i also tried to generate the hash number with a lua script, but that that is even (a little) slower:function ofelia.symbol(stringList); local a = {}; local b = 0; local c = 0; for i = 1, string.len(stringList) do; a[i] = string.byte(stringList, i); end; for i = 1, #a do; b = a[i] + b; c = (b + c) % 1000; end; return c; end;i found this about pure data strings:
"A symbol is a string that is cached (or in fact, permanently stored in a hash table) inside PureData. It can also have some data attached to it. Symbols are a very important part of PureData since a lot of information (e.g. type info) is identified by using them.
The fact that a symbol is permanently resident has the following consequences: * In a PureData external symbol strings can be compared by comparing their pointer values, since there's only one copy in the system. This makes comparison much faster than comparing string characters. Data attached to a symbol won't get lost, since once a created, a symbol stays in the system. If many symbols are created (e.g. automatically in a patch), symbol lookup in the hash table will get slower - this can slow down the whole system as long as PureData is running.
ThomasGrill"
-
This makes comparison much faster than comparing string characters.
True if you've already cached the symbols. If you have to make a call to
gensymin order to do the comparison then it's slower than a string comparison in all cases. (Probably noticeably so since most libraries have fast paths for string comparisons.)If many symbols are created (e.g. automatically in a patch), symbol lookup in the hash table will get slower - this can slow down the whole system as long as PureData is running.
That's not quite true. To be precise:
- As the total number of symbols increases, the lookup time for an arbitrary symbol becomes less predictable. Importantly for realtime performance: your worst-case time for an arbitrary symbol lookup increases.
- As the total number of symbols increases, the time to add a new symbol to the table increases.
For example: the time it takes to look up "set" in the symbol table stays consistent no matter how many symbols you generate in a running instance of Pd. This is because "set" is added to the symbol table at a predictable moment at Pd startup (since it's a method for a core Pd class).
Here's why my distinction matters: suppose you have a patch running. You want to find out if you're doing anything in your patch that is potentially realtime unsafe.
Now suppose I tell you to turn off dsp and run an abstraction that will spam the symbol table with a bunch of randomly generated symbols. Now turn DSP back on.
If your patch is truly realtime-safe then the added bloat shouldn't affect your performance at all. If you start getting dropouts you didn't have before it must mean you are generating new symbols during DSP which isn't realtime-safe.
I think I'm right on what I wrote above, but I haven't tested it. It might help with stuff like this to add a new introspection object to Purr Data for symbols.
Edit: clarification.
-
@jancsika interesting. when i have 100000 instead of 10000 keys the time for searching stays almost the same.
it could be well worth an object or abstraction?
and i wonder why this hash mechanism is not already part of [text]. is there a reason? -
@Jona 100000 keys means a linear search on the average of 100 keys. And that's where each iteration is mostly just comparing symbol pointers (not creating symbols nor doing symbol lookup) so it's quite fast.
[text]is just a wrapper around Pd's main message storage format. That format is very simple. If you wanted to add a hashmap you'd need an additional structure to map the symbol hash to a line number. (And some helper functions to keep track of that mapping.) -
Btw-- here's a nice article that outlines some of the common hash table terminology in the context of realtime embedded systems:
http://users.cs.northwestern.edu/~sef318/docs/hashtables.pdf
The discussion about performance as the number of keys per bucket increases is particularly relevant. Same with the desire for the ratio between the worst-case and average performance to approach one.
It's also instructive to notice the difference in complexity between the simplistic approach Pd uses and their proposed realtime-safe memory-constrained approach. Pd's algo is simple enough that you can read the code and understand what it does straightaway. In fact I'm not sure anyone has ever done the most basic testing on it, or even checked to make sure that it distributes keys uniformly across the buckets (though I assume it does). Yet people seem to be able to use Pd in performances, even large complex patches, without symbol table growth becoming a performance bottleneck.
Edit: to be fair, most users aren't doing things like text processing of arbitrary input during performance. So the limitations of the core language may work to keep users from ever hitting that limit. But I think if you had a big patch with thousands of abstractions containing lots of "$0-"-prefixed symbols inside them you might be able to experience the problem.
