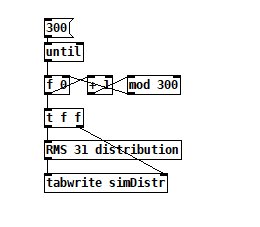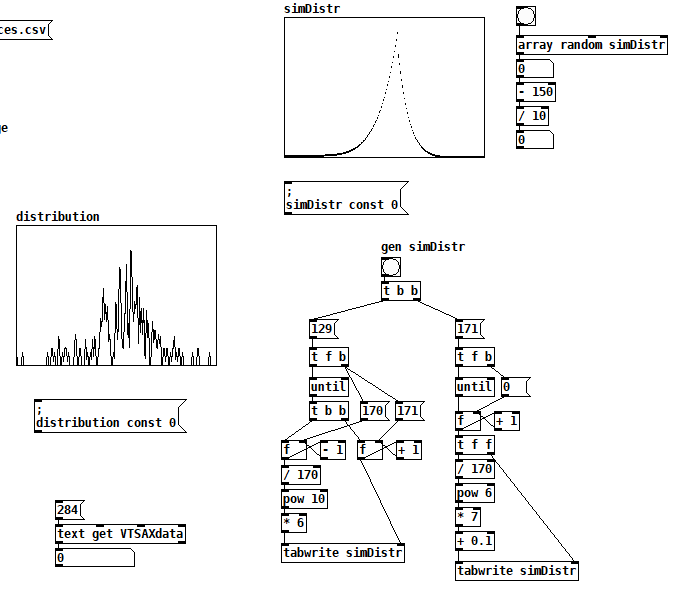
I'm trying to use [array random] to create a random number generator that outputs numbers in a similar distribution to a real-world process. In the snapshot above, the "distribution" table is a histogram of 285 points of real data, and I'm speculating that if I had access to more data, the curve would become smoother.
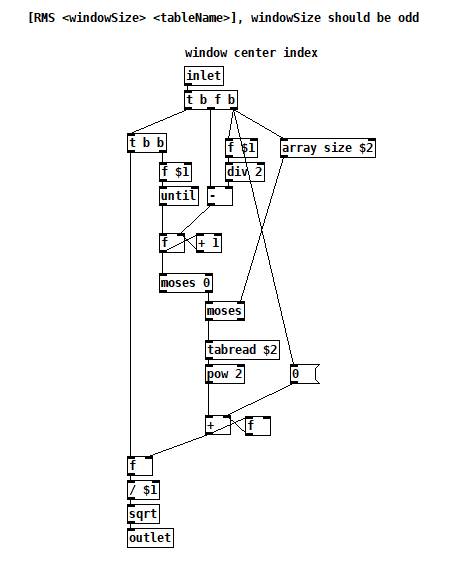
The "simDist" table is just my eyeball attempt to make the idealized version of the real histogram. In tests, it works fairly well, but I'm wondering if it would be better if it was arithmetically derived from the "distribution" table, e.g. uh, I dunno, a moving N-point RMS? I'm sure a data scientist would say "it depends what you mean by 'better'", but I'd be interested to know what options there are and what each is good for. Somehow, low pass filtering doesn't feel right to me because it's a histogram.